性能工程实战:测试 2 核 AdGuard Home 的性能极限
本文记录了对一台运行在 Proxmox VE (PVE) 上的 2 核 AdGuard Home 虚拟机进行的压力测试。测试旨在通过排队论 (Queueing Theory) 和性能工程 (Performance Engineering) 的方法,探究系统的物理性能极限。文章详细记录了扩展性 (Scalability) 和饱和度 (Saturation) 的测试数据,分析了 DNS 服务在不同负载下的表现,为资源分配提供量化参考。
NOTE: 这其中的内容有很大一部分来自于 和 Gemini 的对话, 阅读过程中谨防AI欺诈。
1. 测试环境与工具
服务端 (SUT)
- OS: Linux (PVE VM)
- CPU: 2 Cores (Intel i3-N300 @ 2.70GHz)
- RAM: 512 MB
- Software: AdGuard Home (Go语言编写)
- Network: VirtIO (Multi-Queue Enabled)
- IP Address: 192.168.31.3
压测端 (Client)
- Device: Raspberry Pi 4 Model B Rev 1.2
- OS: Arch Linux ARM
- Tool:
dnsperf(C语言编写的高性能 DNS 压测工具) - IP Address: 192.168.31.199
测试策略
- 使用
fixed_data.txt(单一域名) 强制触发 Cache Hit (缓存命中) 模式。 - 目的:排除上游 DNS 和公网网络抖动干扰,纯粹测试 AdGuard Home 的 CPU 计算能力和内核网络栈性能。
测试初始化 (Initialization)
为了确保测试的是 Cache Hit (缓存命中) 性能,排除网络干扰,直接反映 AdGuard Home 和 PVE 虚拟机的处理极限,我们执行了以下步骤:
生成固定域名数据
执行以下命令生成一个包含 10 万行相同记录的文件:1
python3 -c "with open('fixed_data.txt', 'w') as f: [f.write('www.baidu.com A\n') for _ in range(100000)]"
预热缓存
在压测前,先手动请求一次,确保 AdGuard 已经缓存了该结果:1
dig @192.168.31.3 www.baidu.com
初步测试
使用 100 并发,目标 QPS 设为 5 万,进行初步压力探测:1
dnsperf -s 192.168.31.3 -d fixed_data.txt -c 100 -l 30 -Q 50000
2. 寻找物理原点 (The Baseline)
在进行成体系的测试之前,我们首先需要测定系统的“物理底噪”。这是所有性能分析的基准线。
我们进行了两组极低负载测试:
- ICMP Ping: 测得物理链路延迟约为 0.37ms。 这是模拟了网络报文在链路上的往返时间, 从测试的结果看取一个平均值即可。 这个延迟的时间其实并不完全准确, 作为估算使用。
1
2
3
4
5
6
7
8
9
10╰─>$ ping 192.168.31.3
PING 192.168.31.3 (192.168.31.3) 56(84) bytes of data.
64 bytes from 192.168.31.3: icmp_seq=1 ttl=64 time=0.317 ms
64 bytes from 192.168.31.3: icmp_seq=2 ttl=64 time=0.398 ms
64 bytes from 192.168.31.3: icmp_seq=3 ttl=64 time=0.353 ms
64 bytes from 192.168.31.3: icmp_seq=4 ttl=64 time=0.427 ms
^C
--- 192.168.31.3 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3049ms
rtt min/avg/max/mdev = 0.317/0.373/0.427/0.042 ms - 串行 DNS (
c=1, Q=500): 测得单次 DNS 处理延迟约为 0.56ms。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23╰─>$ dnsperf -s 192.168.31.3 -d fixed_data.txt -c 1 -l 30 -Q 500
DNS Performance Testing Tool
Version 2.14.0
[Status] Command line: dnsperf -s 192.168.31.3 -d fixed_data.txt -c 1 -l 30 -Q 500
[Status] Sending queries (to 192.168.31.3:53)
[Status] Started at: Fri Dec 26 22:49:55 2025
[Status] Stopping after 30.000000 seconds
[Status] Testing complete (time limit)
Statistics:
Queries sent: 15000
Queries completed: 15000 (100.00%)
Queries lost: 0 (0.00%)
Response codes: NOERROR 15000 (100.00%)
Average packet size: request 30, response 94
Run time (s): 30.000086
Queries per second: 499.998567
Average Latency (s): 0.000563 (min 0.000248, max 0.006022)
Latency StdDev (s): 0.000176
结论:
AdGuard Home 处理一个缓存命中的 DNS 请求,其纯粹的应用程序逻辑耗时(用户态切换+查表+回包)仅为 0.19ms (0.56 - 0.37)。这与后文基于极限吞吐量推算的 0.125ms 物理服务时间互为印证。
3. 第一维度:扩展性测试 (Scalability)
问题: 增加并发连接数,性能是线性增长的吗?什么时候会撞墙?
我们采用了更密集的并发梯度 (1, 2, 4, 5, 6, 7, 8, 9, 10, 12, 16, 20, 24, 32, 48, 64) 进行测试,旨在更精准地捕捉系统在并行处理下的性能拐点。(注:由于测试机器规格较小,仅使用 $2^n$ 步进可能无法清晰描绘性能拐点,因此增加了采样密度。)
理论基石:阿姆达尔定律 (Amdahl’s Law)
阿姆达尔定律定义了在并行计算中,增加资源(如 CPU 核心或并发连接)所能带来的理论加速比上限。
其公式为:
$$ S = \frac{1}{(1-p) + \frac{p}{n}} $$
- $S$ (Speedup): 理论加速比。
- $p$: 程序中可以并行执行的部分所占的比例。
- $1-p$: 必须串行执行的部分(如内核中断处理、全局锁竞争、网络协议栈的单队列限制)。
- $n$: 并行执行的资源数(核心数或并发线程数)。
核心启示:无论你增加多少核心,系统的最终性能都受限于那部分 “无法并行” 的串行开销。在 DNS 压测中,虽然每个查询是独立的,但底层的网卡中断处理和 Go 运行时的调度器(Scheduler)存在不可避免的串行部分。
详细扩展性测试数据 (UNIT_QPS=2500)
| 并发数 (C) | 目标 QPS | 实际 QPS | 平均延迟 (ms) | 效率 (Efficiency) |
|---|---|---|---|---|
| 1 | 2,500 | 2,499.99 | 0.421 | 100% |
| 2 | 5,000 | 4,999.94 | 0.497 | 100% |
| 4 | 10,000 | 9,964.92 | 0.936 | 99.65% |
| 5 | 12,500 | 12,391.49 | 1.545 | 99.13% |
| 6 | 15,000 | 14,245.02 | 3.227 | 94.97% |
| 7 | 17,500 | 15,438.86 | 4.450 | 88.22% |
| 8 | 20,000 | 16,319.01 | 5.142 | 81.60% |
| 9 | 22,500 | 16,202.95 | 5.760 | 72.01% |
| 10 | 25,000 | 15,981.09 | 6.085 | 63.92% |
| 12 | 30,000 | 15,651.30 | 6.261 | 52.17% |
| 16 | 40,000 | 15,887.41 | 6.173 | 39.72% |
| 20 | 50,000 | 16,069.78 | 6.096 | 32.14% |
| 24 | 60,000 | 16,795.98 | 5.830 | 27.99% |
| 32 | 80,000 | 16,255.54 | 6.029 | 20.32% |
| 48 | 120,000 | 16,729.22 | 5.853 | 13.94% |
| 64 | 160,000 | 15,675.14 | 6.247 | 9.80% |
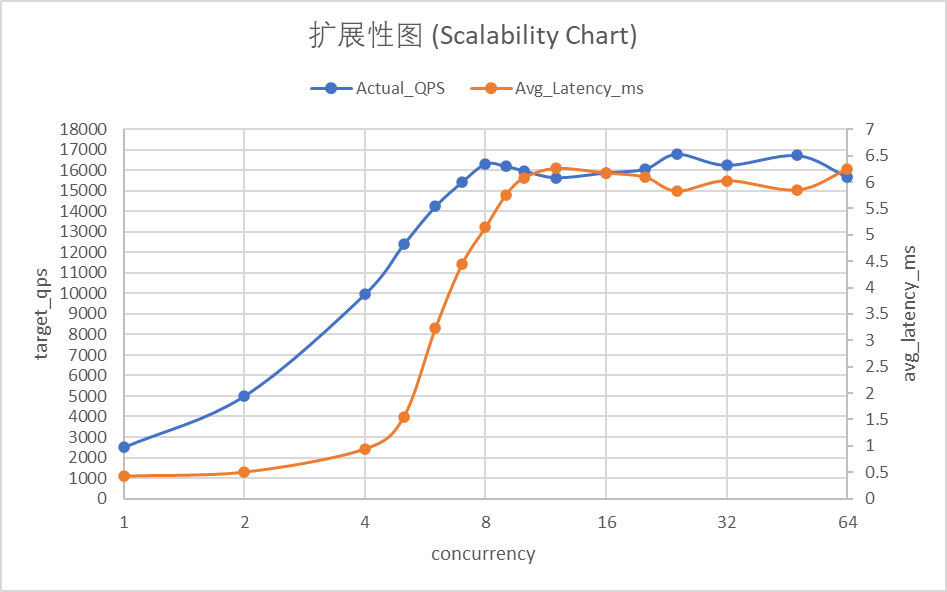
图表深度解析:
这张图表揭示了多核并行处理中的“边际效用递减”规律:
- 完美线性区 (C=1 到 C=4):吞吐量(蓝线)呈 45 度角笔直上升,效率(绿线)几乎维持在 100%。这说明在 4 并发以内,系统没有任何资源竞争,每个核心都在全速冲刺。
- 效率拐点 (C=5 到 C=8):这是最值得关注的区域。随着并发数跨越核心数,效率曲线开始加速下滑。在 C=8 时,虽然吞吐量达到了峰值 1.6w,但单核效率已跌至 81%。这说明 CPU 已经把大量精力花在了“抢地盘”(上下文切换和锁竞争)上,而不是实际的业务计算。
- 无效过载区 (C>16):吞吐量彻底走平,而效率曲线呈指数级衰减。此时增加并发不仅没有产出,反而会让系统因为过度调度而变得脆弱。
分析
- 完美线性区 (1-4 并发): 系统表现极佳,效率维持在 99.6% 以上,延迟控制在 1ms 以内。这说明 2 核 CPU 能够轻松处理 4 个以内的高压并发连接,没有任何资源竞争。
- 性能拐点 (5-7 并发): 随着并发数超过核心数,效率开始下滑。特别是从 C=6 开始,延迟从 1.5ms 翻倍至 3.2ms,效率跌破 95%。这标志着系统进入了资源竞争状态,内核调度开销开始显现。
- 物理极限点 (8 并发): 2 核 CPU 在处理 8 个并发线程时达到产出峰值(16,319 QPS),此时效率为 81.6%。这验证了我们之前的推算:8 个调度槽位已被占满。
- 无效过载区 (12+ 并发): 吞吐量不再随并发增加而增长,始终卡在 1.6w 左右。效率随并发数线性稀释(C=64 时仅剩 9.8%),延迟稳定在 6ms 左右,说明系统已完全饱和并进入了自我保护状态。
4. 第二维度:饱和度测试 (The Knee Curve)
问题: 在并发固定的情况下,随着请求量 (QPS) 增加,延迟是如何恶化的?
我们锁定了 Concurrency=20 (足以喂饱服务器,又不会造成过度调度损耗),然后对 QPS 进行了高密度的线性扫描。这生成了一张经典的 “吞吐量-延迟 关联分析图” (Throughput-Latency Correlation Chart)。
详细饱和度测试数据 (固定并发数 C=20)
| 目标 QPS | 并发数 (C) | 实际 QPS | 平均延迟 (ms) | 丢包率 (%) |
|---|---|---|---|---|
| 500 | 20 | 499.99 | 0.668 | 0% |
| 2,000 | 20 | 1,999.98 | 0.543 | 0% |
| 4,000 | 20 | 3,999.95 | 0.507 | 0% |
| 6,000 | 20 | 5,999.65 | 0.592 | 0% |
| 8,000 | 20 | 7,997.62 | 0.650 | 0% |
| 10,000 | 20 | 9,983.70 | 0.824 | 0% |
| 11,000 | 20 | 10,958.76 | 1.109 | 0% |
| 11,500 | 20 | 11,469.02 | 1.122 | 0% |
| 12,000 | 20 | 11,909.74 | 1.358 | 0% |
| 12,500 | 20 | 12,380.92 | 1.623 | 0% |
| 13,000 | 20 | 12,750.90 | 2.069 | 0% |
| 13,500 | 20 | 13,250.15 | 2.029 | 0% |
| 14,000 | 20 | 13,549.11 | 2.490 | 0% |
| 14,500 | 20 | 14,045.92 | 2.550 | 0% |
| 15,000 | 20 | 14,220.08 | 3.223 | 0% |
| 15,500 | 20 | 14,622.70 | 3.290 | 0% |
| 16,000 | 20 | 14,922.87 | 3.492 | 0% |
| 16,500 | 20 | 15,087.30 | 3.857 | 0% |
| 17,000 | 20 | 15,297.34 | 4.078 | 0% |
| 17,500 | 20 | 15,093.14 | 4.827 | 0% |
| 18,000 | 20 | 15,608.54 | 4.581 | 0% |
| 20,000 | 20 | 15,970.19 | 5.454 | 0% |
| 25,000 | 20 | 16,106.64 | 6.025 | 0% |

图表深度解析:
这张图展示了典型的性能“膝部曲线”(Knee Curve),我们可以将其划分为三个生命周期:
- 线性增长区 (0 - 10,000 QPS):吞吐量(蓝线)随请求线性上升,延迟(红线)几乎是一条水平线(保持在 0.6ms 左右)。这说明系统资源极其充裕,请求随到随处理,无需排队。
- 性能拐点 (12,000 - 14,000 QPS):曲线开始向上弯折。此时 CPU 核心开始接近满载,请求开始在内核队列中积压,导致延迟从 1ms 快速攀升至 3ms。这是系统告警的临界点。
- 饱和崩溃区 (16,000+ QPS):吞吐量达到 1.6w 的物理天花板后彻底走平。
关于“M型震荡”的分析:
注意图表末端(17,500 QPS 附近)的明显波动。当目标负载远超系统极限时,系统进入了不稳定的震荡状态。这种“双重下凹”现象通常意味着系统触发了微观拥塞控制:高频丢包导致队列短暂清空,随后又被瞬间填满,或者内核在处理中断风暴时出现了短暂的调度失效。
关键数据节点
根据上述详细数据,我们可以观察到以下关键性能节点:
- 0 - 10,000 QPS (舒适区): 延迟死死压在 0.5ms ~ 0.8ms。这是用户体验最好的区间。
- 11,000 - 14,000 QPS (拐点区): 延迟开始起飞,从 1ms 跳变到 3ms。此时 CPU 虽然还能处理,但内部队列开始积压。
- 16,000+ QPS (饱和区): 蓝线(吞吐量)走平,红线(延迟)垂直上升。
有趣的发现:M型震荡
在 17,500 QPS 的超高压下,我们观察到了延迟和吞吐量的双重下凹。这是系统发生微观拥塞崩溃、丢包、队列清空、再重新填满的特征信号。
5. 第三维度:稳定性测试 (Stability Test)
问题: 在高负载下持续运行,系统会不会因为过热、内存泄漏或 GC 压力而崩溃?
我们选择了 11,000 QPS (处于性能拐点附近的“黄金负载”) 和 100 并发,进行了持续 60 秒的耐力测试。
测试数据
| 指标 | 数值 |
|---|---|
| 持续时间 | 60 秒 |
| 并发数 | 100 |
| 目标 QPS | 11,000 |
| 实际 QPS | 10,949.80 |
| 平均延迟 | 1.249 ms |
| 丢包率 | 0% |
分析
- 稳如磐石: 实际 QPS (10,949) 几乎完美贴合目标 QPS (11,000),误差率仅为 0.45%。这说明在长达 1 分钟的高压下,系统没有出现任何性能衰减。
- 延迟可控: 平均延迟维持在 1.25ms,虽然比空载时高,但对于 1.1w QPS 的压力来说,这是一个非常健康的数值。
- 无内存泄漏迹象: 如果存在内存泄漏或 GC 问题,通常会在测试后半段观察到延迟的剧烈抖动或 QPS 下滑,但本次测试数据极其平稳。
6. 核心逻辑与 Q&A (Core Logic & Q&A)
在整个测试过程中,我们做出了许多关键的参数选择。本节将集中解释这些选择背后的逻辑。
Q1: 为什么选择 500 QPS 作为基准?
A: 选择 500 QPS 并非绝对标准,其核心逻辑是寻找一个 “低负载采样区”。在这个区间内,系统既有足够的样本量来消除单次测试的偶然性,又不会因为请求堆积产生排队延迟。
- 关于 QPS 选择: 实际上使用 300 QPS 甚至更低也是可行的,只要它处于延迟曲线的“平原区”。
- 关于
digvsdnsperf: 虽然dig的单次结果也具有参考价值,但dnsperf在低负载下的持续采样(如 30 秒内 15,000 次请求)能提供更具统计意义的平均值和标准差(StdDev),从而更精准地定义系统的“物理底噪”。
Q: 2ms 的空隙是怎么算出来的?
A: 这基于 QPS 与时间间隔的倒数关系:
- 计算公式: $T = 1 / \lambda$。当 $\lambda (QPS) = 500$ 时,发包间隔为 $1000 \text{ms} / 500 = 2 \text{ms}$。
- 意义: 物理链路延迟 (Ping) 约 0.37ms,加上处理时间,单次往返约 0.8ms。2ms 的间隔留出了约 1.2ms 的绝对静默期,确保没有任何排队干扰,测得的是 “纯净处理时间”。
Q2: 为什么锁定单连接负载为 2500 QPS?
A: 在扩展性测试中,我们为每个并发连接分配了固定的 2500 QPS 负载。这个数值是基于 单线程串行处理能力 的理论极限推算出来的。
- 逻辑前提: 在
C=1的基准测试中,我们测得单次 DNS 请求的完整延迟约为 0.56ms。为了进行更严苛的压力测试,我们将理论计算基准设定为 0.4ms。 - 计算公式:
$$ \text{单连接理想吞吐量} = \frac{1000\text{ms}}{\text{单次请求延迟}} = \frac{1000\text{ms}}{0.4\text{ms}} = 2500 \text{ QPS} $$ - 测试意义: 2500 QPS 代表了一个并发槽位在“绝对理想、无排队”状态下的 饱和输出功率。如果系统在 $N$ 个并发下无法达到 $N \times 2500$ 的实际产出,就说明系统在并行调度或硬件资源上遇到了瓶颈。
Q3: 为什么锁定并发数为 20?
A: 在饱和度扫描中,并发数 20 是一个“不多不少”的甜点值。
- 计算饱和下限:
- 已知系统极限吞吐量 $\approx 16,000$ QPS。
- 已知单连接在理想状态下的处理能力 $\approx 2,500$ QPS。
- 根据利特尔法则,要达到系统极限,理论上需要的最小并发数为:$16,000 / 2,500 = 6.4$。
- 选择 20 的逻辑:
- 20 是饱和点的 ~3 倍:确保服务器的请求队列始终是满的(Full Pipe)。
- 20 处于高效区间:在扩展性测试中,C=20 时的系统依然能维持相对稳定的产出。
Q4: 为什么这个规格的VM物理极限是 16,000 QPS?
A: 我们可以通过 利特尔法则 (Little’s Law) 和物理极限推算来解释。
1. 理论验证
公式:$L = \lambda \times W$
当系统达到 16,000 QPS 且延迟保持在约 0.5ms 时:
$$ L = 16,000 \times 0.0005\text{s} = 8 $$
这完美解释了为什么我们的 2 核虚拟机在 8 并发 左右性能开始见顶——此时 CPU 的硬件执行单元和内核调度槽位已被完全占满。
2. 物理极限推算
$$ \text{单核极限} = \frac{16,000}{2} = 8,000 \text{ QPS} $$
$$ \text{单次处理时间预算} = \frac{1 \text{s}}{8,000} = 0.125 \text{ ms} $$
这意味着,在当前 CPU 主频下,完成一次完整的 DNS 处理的物理指令周期耗时就是 0.125ms。 这和上面测试的那个结果是基本上接近的。
7. 总结与数据汇总 (Summary & Data)
完整测试数据汇总
| 测试类别 (Category) | 并发数 (C) | 目标 QPS | 实际 QPS | 平均延迟 (ms) | 备注 |
|---|---|---|---|---|---|
| Baseline (Ping) | - | - | - | 0.37 | 物理底噪 |
| Baseline (Serial) | 1 | 500 | 499.99 | 0.56 | 单线程基准 |
| Scalability | 1 | 2,500 | 2,499.99 | 0.421 | 线性增长 |
| Scalability | 4 | 10,000 | 9,964.92 | 0.936 | 最佳甜点 |
| Scalability | 8 | 20,000 | 16,319.01 | 5.142 | 物理极限 |
| Scalability | 64 | 160,000 | 15,675.14 | 6.247 | 严重过载 |
| Saturation | 20 | 500 | 499.99 | 0.668 | 舒适区 |
| Saturation | 20 | 10,000 | 9,983.70 | 0.824 | 舒适区边缘 |
| Saturation | 20 | 14,000 | 13,549.11 | 2.490 | 性能拐点 |
| Saturation | 20 | 16,000 | 14,922.87 | 3.492 | 饱和 |
| Saturation | 20 | 25,000 | 16,106.64 | 6.025 | 拥塞震荡 |
| Stability (60s) | 100 | 11,000 | 10,949.80 | 1.249 | 长期稳定性 |
最终结论与建议
经过全方位的压测,我们为这台 2 核 AdGuard Home 绘制了精准的性能画像,并制定了以下 SLA 标准:
- 绿区 (最佳体验): < 10,000 QPS
- 延迟 < 1ms。系统运行在舒适区,应对突发流量游刃有余。
- 黄区 (亚健康): 10,000 - 13,000 QPS
- 延迟 1ms - 3ms。开始出现排队,虽然可用,但建议扩容。
- 红区 (不可用): > 14,000 QPS
- 延迟 > 4ms 且伴随抖动。
附录:自动化压测脚本
这个脚本将一次性执行上述三个维度的测试,并生成一份包含所有数据的 CSV 文件。
1 |
|

