Redis 笔记
ElastiCache主要概念
ElastiCache nodes
A node is the smallest building block of an ElastiCache deployment.
node is a fixed-size chunk of secure, network-attached RAM.
总结来说, 就是ec2实例上面跑了相同版本的Engine for Redis。ElastiCache for Redis shards
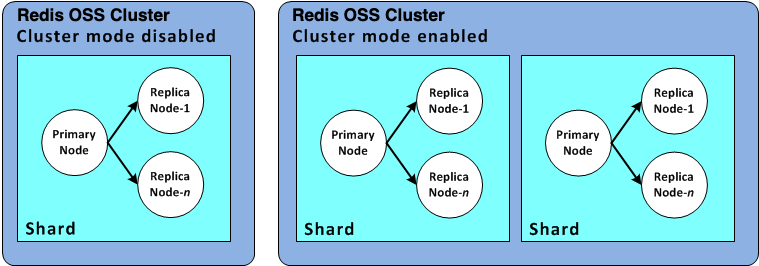
A Redis shard (called a node group in the API and CLI) is a grouping of one to six related nodes. A Redis (cluster mode disabled) cluster always has one shard.
Redis (cluster mode enabled) clusters can have up to 500 shards, with your data partitioned across the shards.Shard 是多个 Nodes 的集合, 或者叫作节点组. 一个Shard包括的节点有不同的角色, 一个Primary 和 最多5个 Replica.
ElastiCache for Redis clusters
A Redis cluster is a logical grouping of one or more ElastiCache for Redis shards. Data is partitioned across the shards in a Redis (cluster mode enabled) cluster.
集群模式关闭, 1 Cluster – 1 Shard – 1 - 6 Nodes: 1 Primary and 5 Nodes
集群模式开启, 1 Cluster – 500 Shard – 1 - 6 Nodes: 1 Primary Per ShardElastiCache for Redis replication
Redis (cluster mode disabled) clusters support one shard (in the API and CLI, called a node group).
Redis (cluster mode enabled) clusters can have up to 500 shards, with your data partitioned across the shards.每个Replica都是Primary中全部数据的复制。 Replica使用异步的方式进行与Primary的数据同步。
第一次 psync2 全量复制所有内存当前存储的数据, 后续使用redis的增量复制。
AWS Regions and availability zones
目前中国区不能使用 GlobalStore, 并且Region之间也是无法相互同步数据的。 在不同的az 之间可以做高可用来降低停机的时间。ElastiCache for Redis endpoints
An endpoint is the unique address your application uses to connect to an ElastiCache node or cluster.Redis 禁用集群模式的单节点端点
单节点的集群端点用于读取和写入. In one word, Single Primary, read and write at one point.
用这个节点的 Endpoint 即可。Redis 禁用集群模式的多节点端点
多节点有两个不同的端点, Primary 端点总是连接到Primary 节点,故障切换会切换这个dns指向的后端。
Reader Endpoint 在所有的 Replica节点之间分流Connection 用来提供读取行为。
用控制台上面的 Primary Endpoint 和 Reader Endpoint
- Redis 启用集群模式的端点
集群模式下, 只是配置一个endpoint, 但是连接到Endpoint之后, 客户端可以发现所有的主节点和从节点。
** 用Configuration Endpoint 可以找到集群内部的每一个 Primary 和 Replica节点 **
ElastiCache parameter groups
Cache parameter groups are an easy way to manage runtime settings for supported engine software. Parameters are used to control memory usage, eviction policies, item sizes, and more.简单来说, 创建每一个配置文件在aws的控制台上, 可以调整一部分Redis的参数, 然后可能在集群内可以实时生效, 也可能需要触发一次Failover才能生效。
elasticache的参数管理通常来说, 改动了参数组中的几个参数可能会需要重启节点:
- activerehashing
- databases
ElastiCache for Redis security
PENDING… Maybe follow offical guide.ElastiCache security groups
创建集群的时候需要指定一个安全组, 需要放行 6379 port, DONE。ElastiCache subnet groups
子网组是运行 Redis 的所有子网的集合, 创建一个子网, 让托管的节点的把ENI放在这个子网里面, 私有子网。ElastiCache for Redis backups
备份特定时间的数据, 可以使用这个用来还原成新的集群, 或者是创建一个集群的种子, 备份中包括所有的data, 和一部分集群的metadata。
bgsave 或者 forkless save, 这两个取决于是否有足够的内存空间, 当空间充足的时候使用的默认的 bgsave, 但是肯定的是, bhsave 会有性能的开销,所以最好是使用副本节点来创建备份或者快照。
对于forkless本身是另一个机制,但是forkless会尝试delay 写入的延迟,从而确保不会积累过多的change 导致内存压力过大失败。ElastiCache events
PENDING… Maybe follow offical guide.
Redis 缓存穿透, 击穿 和 雪崩
穿透
主要是指异常的查询请求, 缓存未命中的场景下直接访问后端, 后端承载了大量请求导致的崩溃。
目前看到需要两个条件:
- 数据在缓存层未命中。
- 大量的请求转移到了后端。
- 请求的数据可能在缓存层 以及 后端都不存在。
避免的方法可能有:
- 在redis 前面添加一个 BloomFilter, 在请求进来的时候进行过滤, 对于异常的请求直接拒绝或者返回一个NULL。
- 提前缓存一部分数值为 NULL 的数据, 在缓存层直接接下这些请求。这个本身是有点问题的。
击穿
这个概念是指的 少部分热点数据被大量的查询时候, 数据突然从缓存中消失, 可能是过期也可能删除等等, 这样有大量的相同请求发送到后端。
解决方案:
- 设置部分数据永远不过期。
- 后端进行加分布式锁。
雪崩
批量的热数据过期, 这时候大部分的请求可能还在继续尝试查询不同的数据,直接将这些请求发送到了后端的数据库, 数据库崩了。
解决方案:
- 创建多个实例, 和副本来提高可用性。
- 后端加锁限流。
- 调整过期时间, 让不同的数据过期的时间错开,防止批量的key 相同的时间过期。
总结起来就是, 避免缓存在特定的场景下失效, 想各种方法保护缓存的可用性。
More Note
COB: Client Output Buffer, Primary 向 Replica 同步数据使用, Max Memory 没有计算这部分的内存, 使用的是Redis引擎之外的内存(os管理的内存)。
Policy : LRU 不严格, 随机选择三个。maxmemory-sample: 3, 可以调大。 sample越大, 信号的时间越长。
Reclaim策略里面, 每秒扫描200个key, 如果数据量比较大的话, Redis会进入loop阶段, 反复尝试Reclaim到25% 以下。
可以尝试使用 scan 命令扫描全部的数据, 遍历所有的key,这样会触发lazyway主动进行回收。
扫描的指令:
1 | scan 0 match * count 20000 |
LRU vs LFU
为了保持主从一致, primary 上过期或者删除的key, 会同步发送一个显式的 delete 指令, 这个会统计在replica的settypecmd。
snapshot里面的数据在恢复的时候,会检查key 的ttl , 如果超过会直接删除。
在Redis内存与物理内存mapping由操作系统的虚拟内存管理器 和 指定的内存分配器进行处理。
关于Info指令的所有参数的解释:
https://redis.io/commands/info/
1 | localhost:6379> info memory |
内存结构
Redis的内存中主要是如下数据:
用户数据
用户数据是作为内存的数据库的关键,也是占用Mem最多的部分, 计算在 used_memory 中。 数据 和 数据结构。
自身进程的内存
这部分是Redis自己占用的内存, 代码, 常量池等等。
缓冲区
三大缓冲区
1. 客户端缓冲区
1. 输入缓冲区: 客户端输入指令Buffer, 输入缓冲区默认是每客户端 1GB, 不计入maxmemory, 无法配置。
2. 输出缓冲区: 返回响应结果的Buffer, 可以调整输出缓冲区的大小。 通过 client-output-buffer-limit 配置
1
2
3
4client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds>
client-output-buffer-limit normal 0 0 0 # 会被限制在maxmemory中
client-output-buffer-limit slave 256mb 64mb 60 # 不会限制在maxmemory
client-output-buffer-limit pubsub 32mb 8mb 60 # 客户使用Pub/Sub Channel 的时候会用, 比较少看到客户使用
Usedmemory 大于 Maxmemory 原因是 SlaveCOB 不计算 Maxmemory, 不会触发Evcation。
2. 复制缓冲区
1. 复制缓冲区: 主要是全量复制的时候使用的空间. 主从同步的时候使用的是 COB 缓冲区。
2. 复制积压缓冲区: 增量同步的缓冲区, 使用参数 repl-backlog-size 配置, 控制是否是增量或者全量同步。 backlog 越大, 越容易进行增量。
3. AOF 缓冲区(这玩意儿好像Ecache里面没有.
1. AOF缓冲区: 写AOF日志异步落到磁盘的Buffer
2. AOF重写缓冲区: AOF重写流程中使用的Buffer
内存碎片
内存碎片有外部碎片 和 内部碎片:
- 外部碎片指os分配内存的时候造成的碎片, 这个部分的碎片主要是和os申请的时候才会出现。 ( 测试的过程中发现, 如果Key过期了, 那么redis是会将内存归还给os的, 那么下次再使用的时候还是会有新的碎片。)
- 内部碎片是 redis 使用的Memory Allocator 分配造成的碎片。
- 参数组中可以有autodefrag参数可以触发Redis 主进程的内存规整。
一些参数
Used Memory
1 | used_memory:938464 |
这里面的指标包括了如下的数据:
KeyValue 的存储,用户数据。
InternalOverload: 内部开销, 表示Redis支持的数据类型的信息。
RSS
1 | used_memory_rss:10747904 |
RSS指标记录的是操作系统已经分配给 RedisInstance 的物理内存大小, rss的这个指标还包括了内部碎片。
造成内存碎片的原因是:操作系统低效的内存分配行为。
Max Memory
1 | maxmemory:1103269725 |
Max Memory 包括哪些部分
根据Redis的文档,MaxMemory的限制主要影响以下几个方面的内存:
- Redis中存储的键值对数据,包括字符串、列表、集合、哈希表、有序集合等类型。
- Redis中使用的数据结构和对象,例如字典、跳跃表、压缩列表、整数集合等。
Ecache 的MaxMemory 是基于节点类型的固定数值, 无法修改。
设置MaxMemory的方法
1 | localhost:6379> CONFIG GET maxmemory |
底层的物理内存不能很容易的被操作系统释放, 因为可能需要删除的数据 与 依旧有效并使用中的数据 在相同的物理内存页中。
因此redis会在需要的时候分配内存, 在回收的时候进行程序侧的回收, 并不将内存完全free给操作系统。内存分配器会尽可能的使用RSS已经分配给程序的内存。
如果需要做内存预留, 那么应该基于历史的峰值来进行调整。
1 | used_memory_peak:1134048 |
mem_fragmentation_ratio
1 | mem_fragmentation_ratio:11.46 |
Memory Fragmentation Ratio = Used Memory RSS / Used Memory
内存碎片比率:
Memory Fragmentation Ratio < 1 # 表示已经有数据被写入交换分区,这通常是一个异常的指标。
Memory Fragmentation Ratio > 1 # normal
Memory Fragmentation Ratio > 1.5 # normal
指标计算的方式导致可能并不能准确的体现发生的问题, 现在比较新的版本更加推荐查看下面的指标:
1 | allocator_frag_ratio:1.08 |
解决内存碎片的方法
- Restart Redis.
- 修改参数, 激活Redis的自动碎片整理在参数组中开启。activedefrag 开启这个参数可能会造成延迟变高, 由于内存的整理也是需要在内存中进行数据迁移和调整的。
3. Limit memory swapping( 这个没看懂。 - 改变内存分配器( 指升级Redis的版本
或者
当存储的数据长短差异较大时, 以下场景容易出现高内存碎片问题:
- 频繁做更新操作, 例如频繁对已存在的键执行append、 setrange等更新操作。
- 大量过期键删除, 键对象过期删除后, 释放的空间无法得到充分利用, 导致碎片率上升。
出现高内存碎片问题时常见的解决方式如下:
- 数据对齐: 在条件允许的情况下尽量做数据对齐, 比如数据尽量采用数字类型或者固定长度字符串等, 但是这要视具体的业务而定, 有些场景无法做到。
- 安全重启: 重启节点可以做到内存碎片重新整理, 因此可以利用高可用架构, 如Sentinel或Cluster, 将碎片率过高的主节点转换为从节点, 进行安全重启。
内存驱逐
当 Redis 内存使用达到 maxmemory 时,需要选择设置好的 maxmemory-policy 进行对老数据的置换。
下面是可以选择的置换策略:
The following policies are available:
noeviction: 达到内存限制时不保存新值。当数据库使用复制时,这适用于主数据库
allkeys-lru: 保留最近使用的键值;删除最近使用最少(LRU)的键值
allkeys-lfu: 保留经常使用的key;删除最不经常使用(LFU)的key
volatile-lru: 删除过期字段设置为 true 的最近最少使用的key。
volatile-lfu: 删除过期字段设置为 true 的最不常用key。
allkeys-random: 随机删除key,为新添加的数据腾出空间。
volatile-random: 随机删除过期字段设置为 true 的key。
volatile-ttl: 删除过期字段设置为 true 且剩余生存时间(TTL)值最短的key。
如果没有指定TTL, 那么volatile的驱逐规则就相当于 noeviction.
key过期回收
Redis有两种方式:
- Lazy Way: 当请求这个key 发现他已经过期的时候, 清理。
- Active Way: 每100ms过期一小部分key。
主动过期的方式每100ms扫描20个key(带有 TTL 的), 也就是每秒可以扫描200个key标记为过期。如果依旧有超过25%的key被标记为过期,那么就再来一次。
如果过期的时间比较合理, 那么大约会有25% 左右的key处于过期的状态。
可以使用scan指令来尝试访问key,scan到的key如果已经过期会被回收。
1 | SCAN 0 MATCH *example* COUNT 20000 |
预留内存: 通常是 25% , 保留用来进行备份, bgsave 来使用。
交换
内核使用交换空间的两个情况:
- 系统处于内存压力下。
- 有些内存页面已经很长时间没有被访问了, 内核会将这些页面放入交换中,通常在Redis上不会发生。
可能导致使用swap的场景:
- 需要存储的数据超过物理内存的总量, 或者由于COB的使用率过高。
- 高内存碎片。
- 较高的连接数。
- 系统进程或者RBD AOF写入大文件, 给系统增加了压力, 导致使用了交换分区。
通常情况使用交换是一定会发生的, 并且是正常的, 不会导致性能的下降, 因为swap指标收集的是操作系统指标, 包括非Redis内的数据被换出的情况, 通常可以使用 maxmemory_human 大于 used_memory_rss_human 来进行判断, 或者是 内存碎片 mem_fragmentation_ratio 小于 1.
Refer:
- https://www.jianshu.com/p/d39f087850c9
- Understand VMM: https://www.kernel.org/doc/gorman/html/understand/
- Understand Memory Fragmention: https://jacktang816.github.io/post/memoryfragmentation/

