RDS QPS 下降引发的网络流控分析记录
找到了另一个大佬对于TCP在linux内核的分析和测试: Link
Topic 1 现象
看到一个朋友的问题, 由 RDS QPS 下降引发的网络问题分析:
引用原文的问题描述:
这个问题一开始是在进行RDS实验的时候发现的。最初的情景是,多台机器同时对数据库进行select和insert操作时,会发现insert操作会造成select操作qps大幅下降,且insert操作结束之后select操作的qps仍不能回升。起初以为是RDS的问题,但是在复现问题、监控RDS之后发现RDS的压力其实很小。于是开始怀疑是网络的问题,在简化了场景和操作之后,发现能在过去做tcp实验的机器上复现,于是用这个更简单的场景进行问题复现和分析。
正确答案以及复盘: https://yishenggong.com/2023/05/06/why-does-my-network-speed-drop-cn/
感谢大佬@plantegg 提供的这个案例和知识星球, tcp协议和 os 网络系统的分析我之前真是一句都说不出来, 这次确实完整的走了一遍网络的部分。
下面是我的一些思路和资料整理:
看完了问题的描述, 我基本上可以给出一个经验的判断,这个问题是aws t2实例的流控, 因为表现和之前的测试非常一致, 为了确认这个问题我又进行了相关的测试,基准信息如下:
实例类型:t2.micro
实例的基准带宽: 64Mbps
实例的突增带宽: 1Gbps
实例的EBS规格: 3000 IOPS, 100GB根卷存储, 125MiB/s
实例的OS : AmazonLinux2023.
Congestion: Cubic
具体的测试方法:
- 启动4个实例 t2.micro, hostname 分别是 nginx \ client1 \ client2 , 方便测试和区分实例; 启动一个额外的实例Client3 来尝试验证是不是流控。
- nginx上面启动一个Nginx server, 发布一个 2GB 大小的文件; Client 1、 Client2 两个实例上面使用curl命令下载。
- 尝试保持这个流量一段时间之后, 带宽会被限制到64 Mbps。
- 由于是流控的问题, 所以现象会稳定出现。
Summary:
我理解这个应该是一个对tcp流的限制, 所以验证这个问题的方法是启动一个iperf的服务并重新生成流量, 如果是流控的话, 那么新的流量应该不受限制, 简单的证明方式就是在Nginx Server上面启动一个Iperf3 的 Server , 然后在发生降低速度的时刻, 使用 Client3 iperf 测试 Nginx Server, 这个时候观察到的现象是两个原有网络链接的速度还是很低, 但是iperf3 的测试网络吞吐量是比较高的。
t系列的实例都是突增类型, 可以允许一定的时间使用超过实例基准性能的资源, 在网络流量超过基准性能一段时间之后, 实例的带宽会被限制。 之前真的一直都没有思考过实例的带宽限制都是怎么做的, 让我在描述更多的细节我也确实无法提供, 借着这个机会,深入研究一下。
重新开始分析这个问题:
分析网络抓包看看,被限速的是Server的实例, 所以直接看Server的抓包.
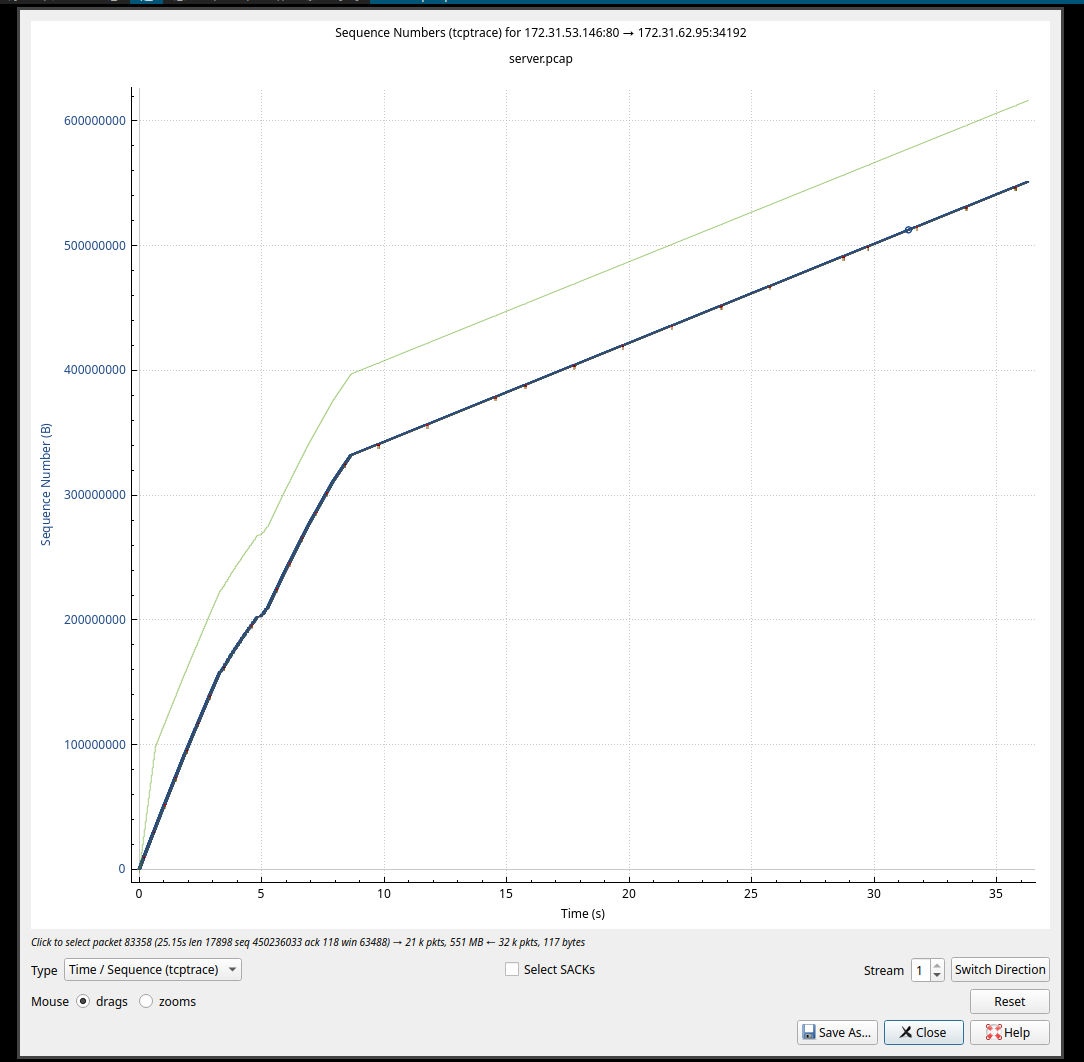
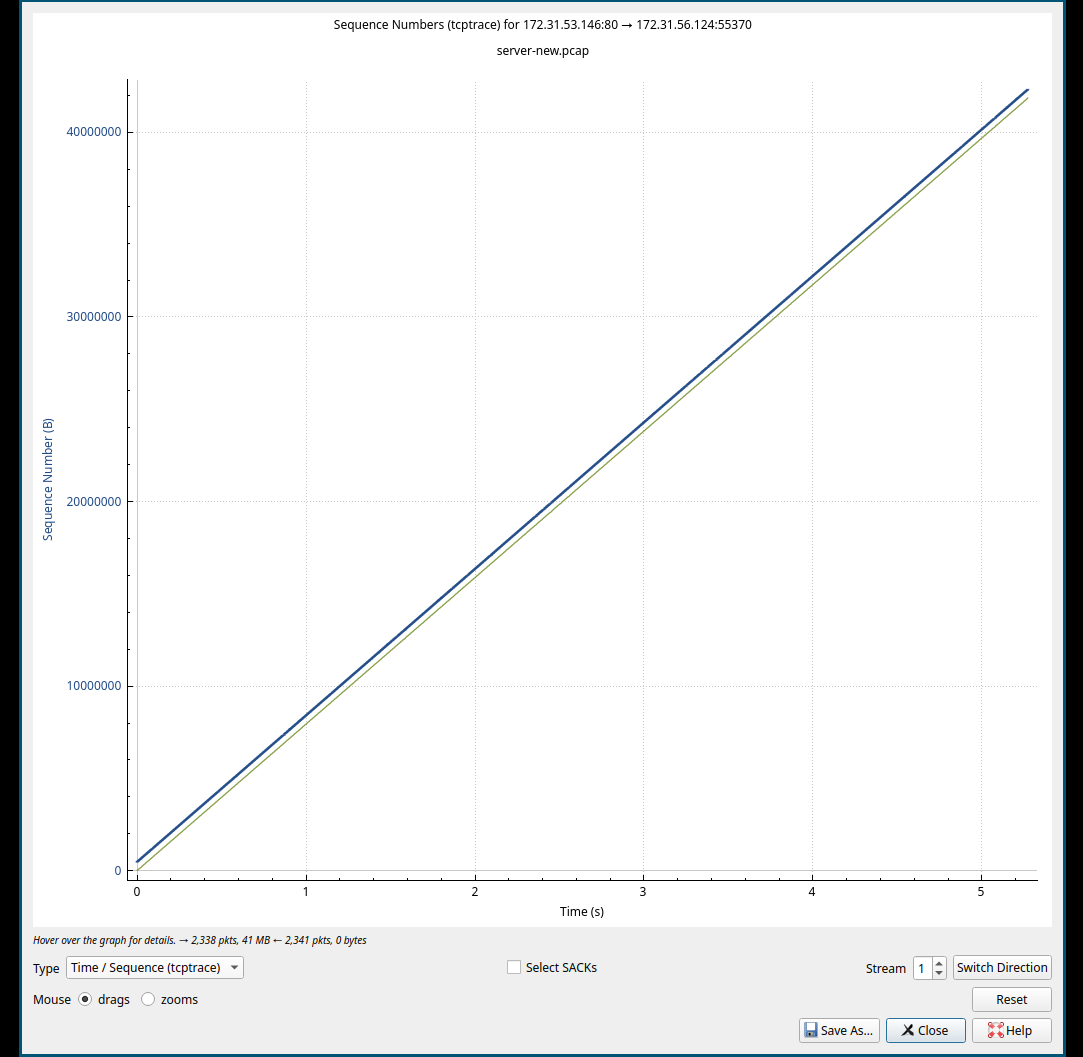
贴一个我自己抓包截图,两个不同的流:
- Server to Client 1:
- Server to Client 2:
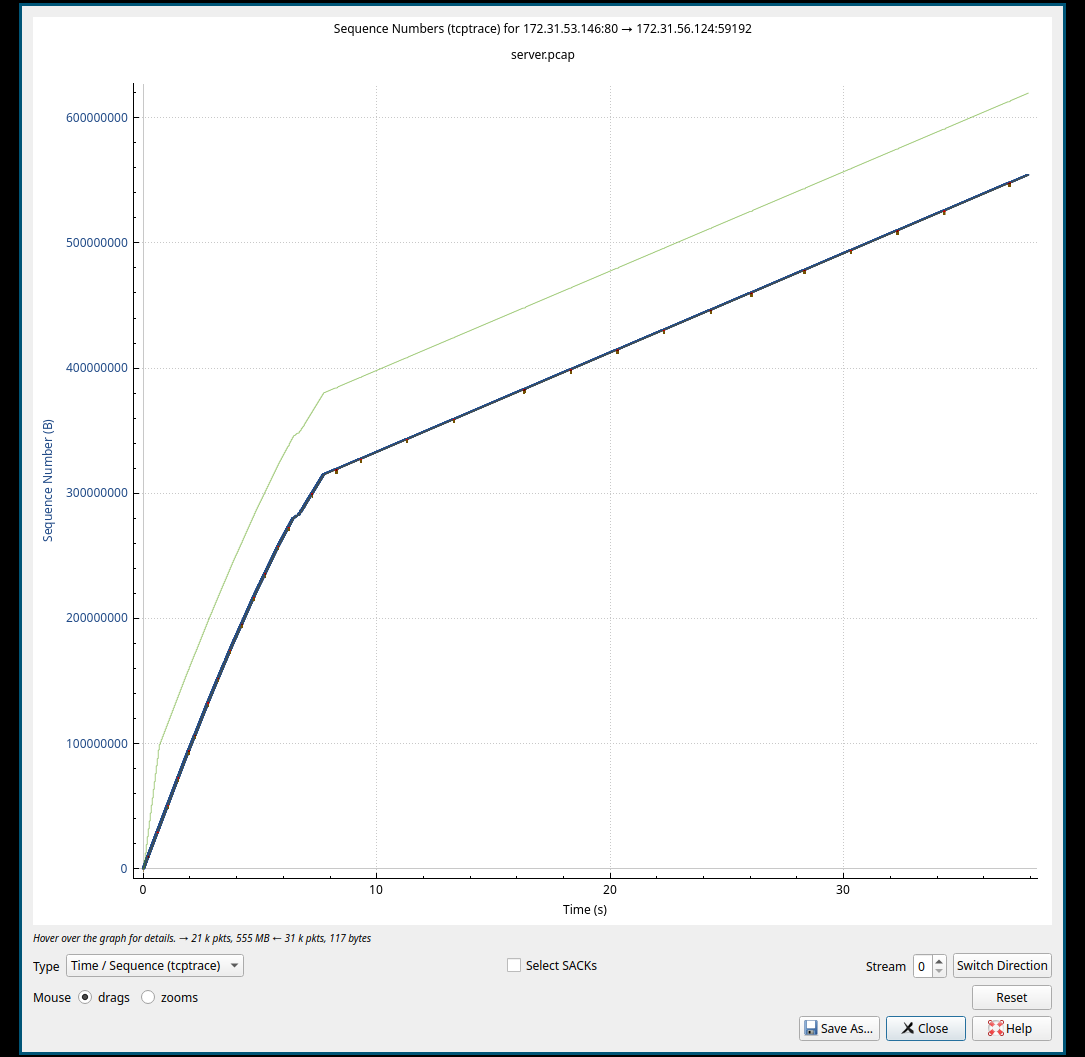
对与上面的两个截图来看, 斜率表越大,下载速度越快, 在斜率较大的前半段, 并未发生任何的TCP异常; 后半段斜率变小的期间,一直有规律的红色标记, 那个标记对应到抓包的结果中,是快速重传的数据包, 并且发生快速重传的时间比较规律, 这类规律的快速重传影响了传输的速度。
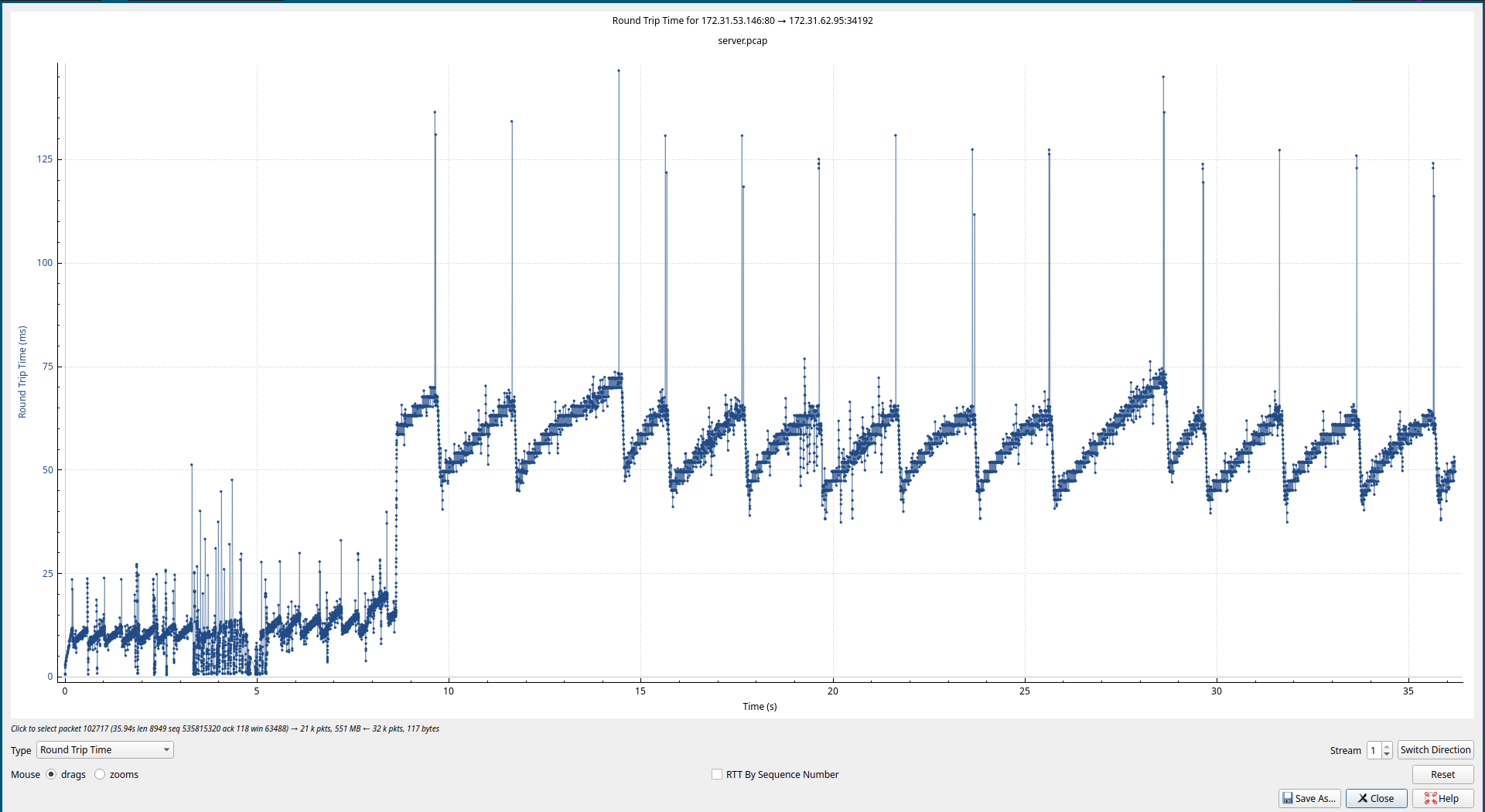
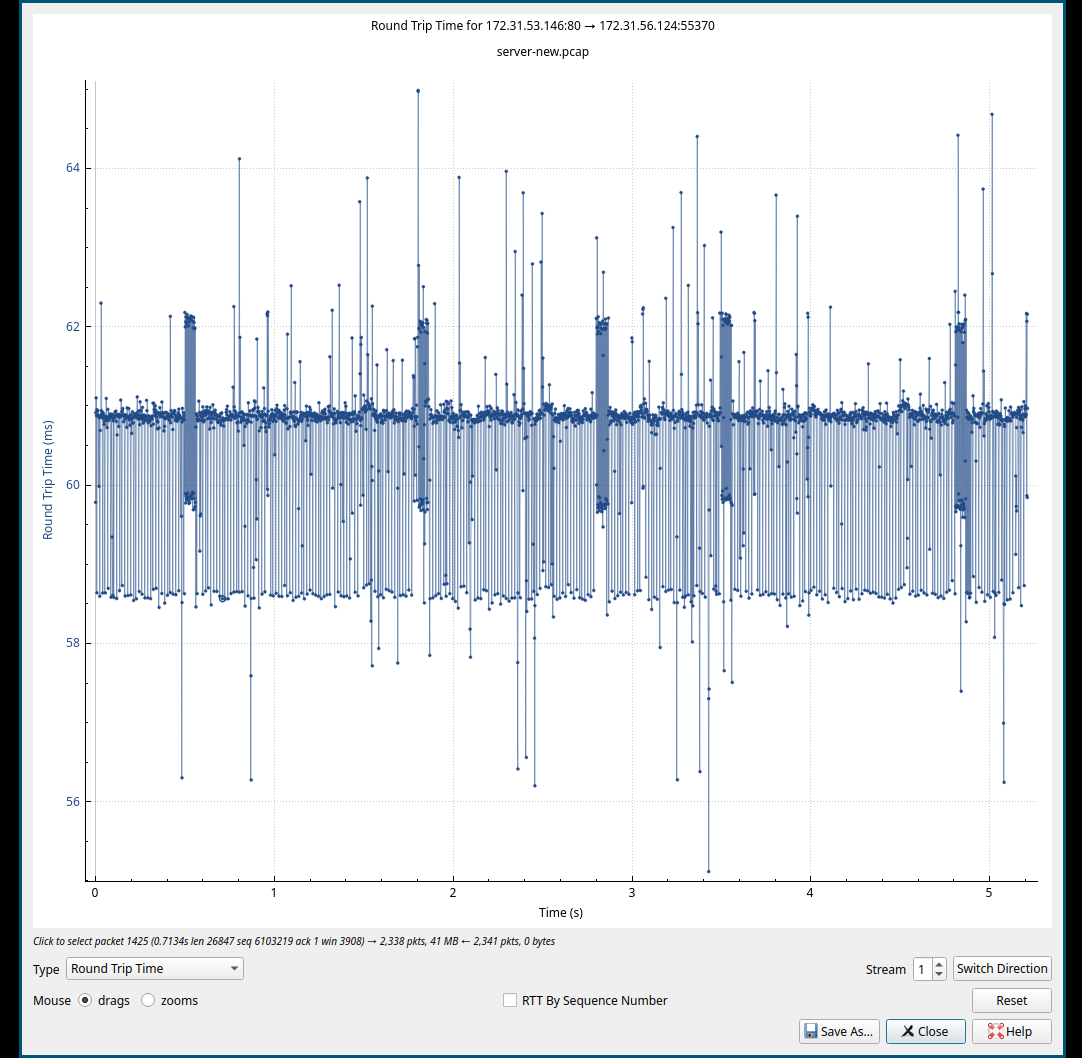
查看RTT的变化, 截图如下:
Server to Client 1:
Server to Client 2:
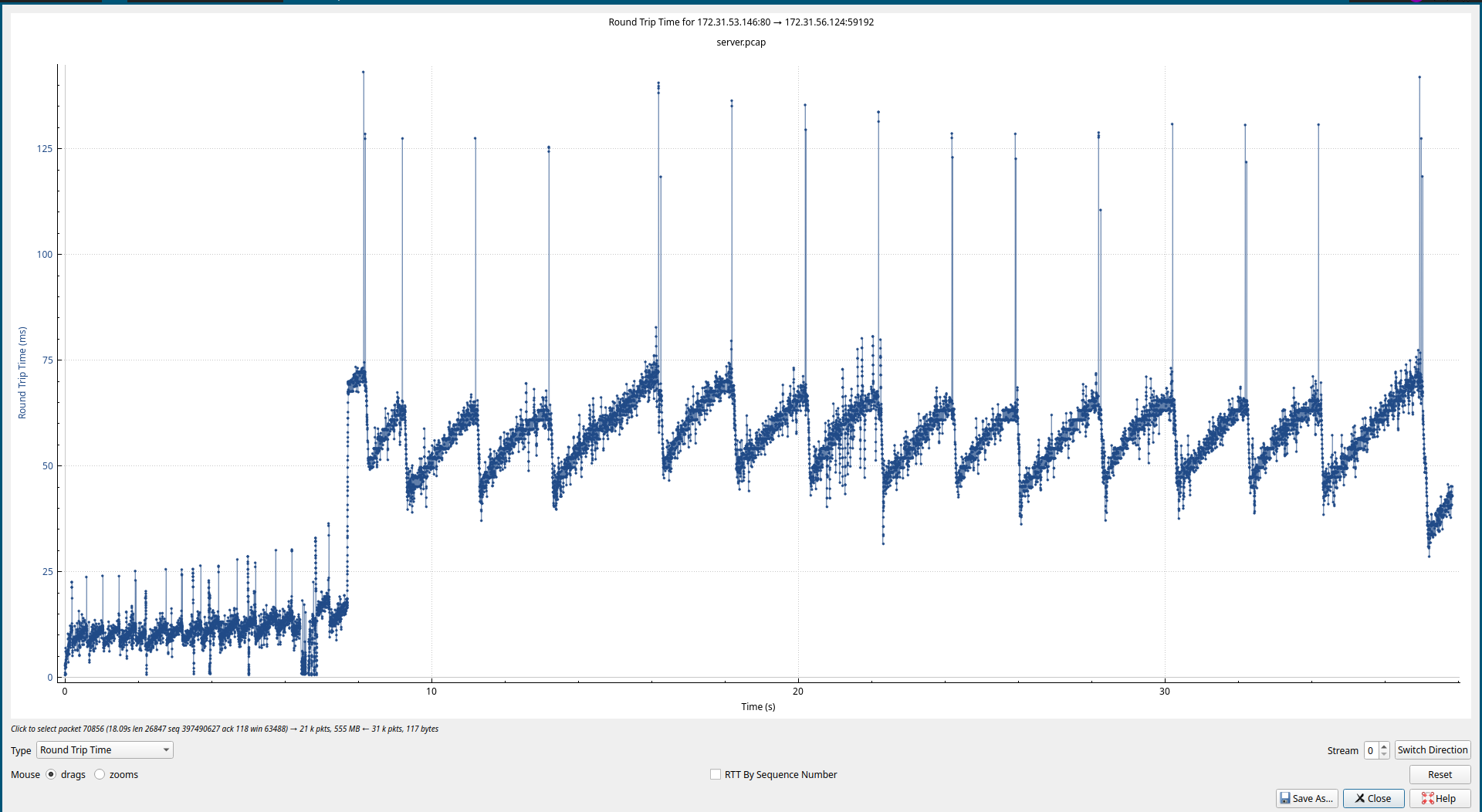
上面的这个部分可以看出整体增大了RTT ,基于之前的tc流控测试,rtt增大的链路上, 发送和接收的窗口需要相应的增大, 才能保证带宽的利用率较高。 按照实验更增加 wmem 和 rmem, 三个实例的设置都增加, 增加之后的速度并没有改变, 依旧还是被限制的水平。RTT从抓包的结果上面来看就是有明显的变化。
查看Server 实例的CWND, 这个CWND的记录直接使用命令行看:
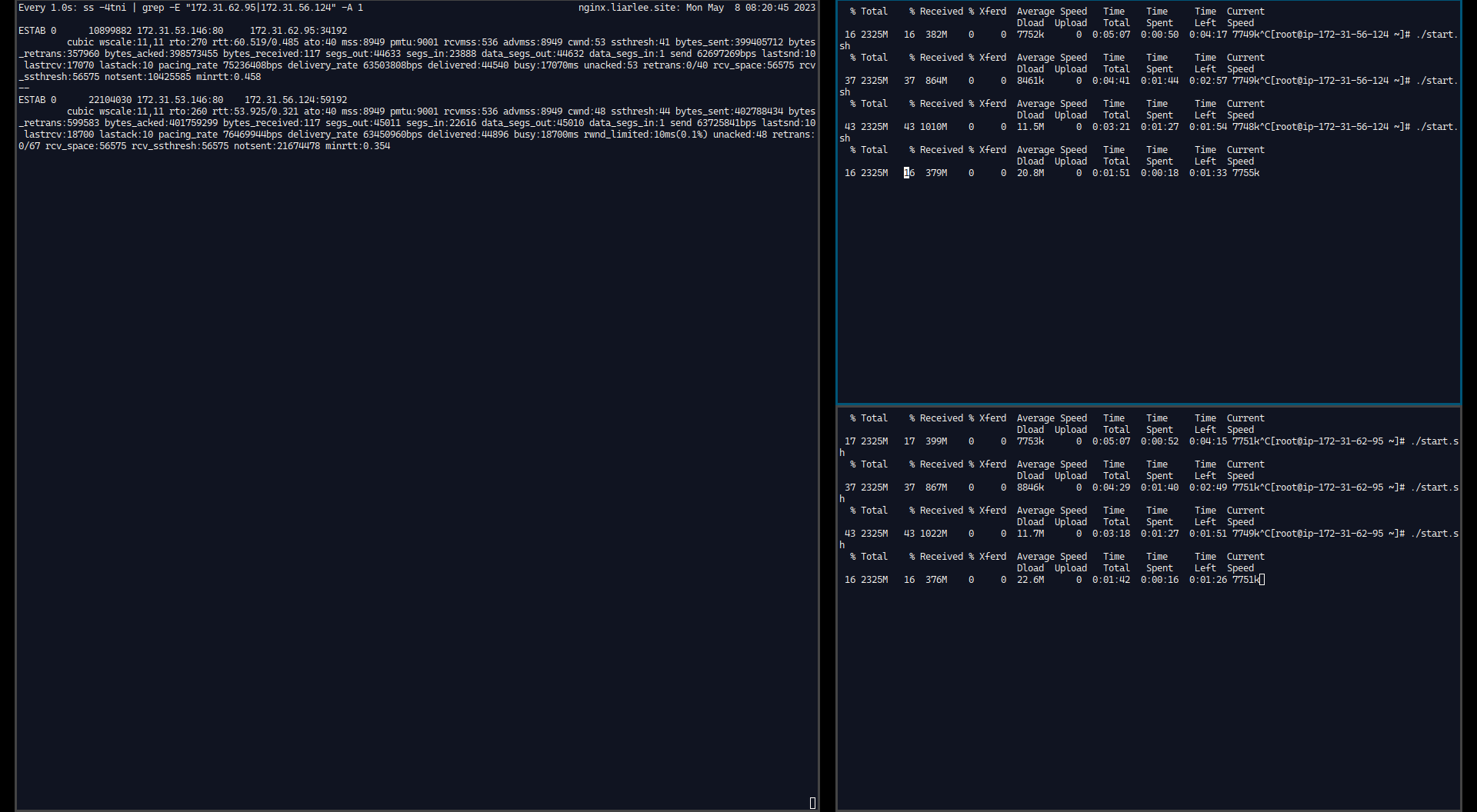
左侧是Server上面的命令行执行结果 命令是
ss -4tni, 命令输出的结果中, 有当前的TCP链接的 RTT, CWND的值, 可以观察到, 到两个Server的链接中RTT的值 ~60ms 左右, 我使用了watch 0.1s来执行ss命令和观察, 重点关注上面的几个参数, 可以发现这几个数值的范围如下:RTT ~ 50ms ~ 70ms 之间变化的频率基本上与cwnd的变化频率一致。
CWND 40 - 64 之间变化, 到达64之后回落到40左右, 然后快速提高到64再回落。
引用一个描述比较清晰的中文文章,其中也介绍了常见的几种拥塞控制算法的模式, 帮我大概理解了下网络的部分:
TCP 连接建立后先经过 Slow Start 阶段,每收到一个 ACK,CWND 翻倍,数据发送率以指数形式增长,等出现丢包,或达到 ssthresh,或到达接收方 RWND 限制后进入 Congestion Avoidance 阶段。1
从另一个文章中找到了如下的一个公式:
因此想要充分利用带宽,必须让窗口大小接近 BDP 的大小,才能确保最大吞吐量。
我们通过如下的例子来讨论一下,究竟 rwnd 和 cwnd 的值与理论最大使用带宽的关系是什么?
min(cwnd, rwnd) = 16 KB RTT = 100 ms 16 KB = 16 X 1024 X 8 = 131072 bits 131072 / 0.1 = 1310720 bits/s 1310720 bits/s = 1310720 / 1000000 = 1.31 Mbps因此,无论发送端和接收端的实际带宽为多大,当窗口大小为 16 KB 时,传输速率最大只能为 1.31 Mbps 。2
可以看到上面的公式中的第一个, 在计算的时候会在cwnd, rwnd 两个指标中选取最小的生效, 那么基于上面的变动, 我们已经把wmem , rmem 都改到了较大的值, 那么这个时候较小 的就是 cwnd 了, 这个值增加不上去就无法充分的利用带宽。
那么现在的问题变成了为什么 cwnd 无法继续增长?
Cubic 在 BIC 的基础上,一个是通过三次函数去平滑 CWND 增长曲线,让它在接近上一个 CWND 最大值时保持的时间更长一些,再有就是让 CWND 的增长和 RTT 长短无关,即不是每次 ACK 后就去增大 CWND,而是让 CWND 增长的三次函数跟时间相关,不管 RTT 多大,一定时间后 CWND 一定增长到某个值,从而让网络更公平,RTT 小的连接不能挤占 RTT 大的连接的资源。1
如果cwnd的大小在拥塞避免之后是基于时间来进行增长的,那么就可以结合上面我观察到的现象, 基本上过一段时间就会出现一定量的快速重传(抓包结果), 周期性的RTT 与 cwnd的变化(命令输出结果)比较吻合了。
基于上面的命令输出结果可以认为确实是通过RTT的增加 + 丢包控制 CWND, 压着CWND的值上不去的原因就是快速重传, 让cwnd随时间增大之后快速重传, 然后触发拥塞避免, 回退到较低的值, 然后开始循环。
感谢Shuo Chen 和 Hao Chen 大佬的测试分析思路以及工具,反复的理解这个Thread里面的说法, 现在基本上可以抓住这个问题的逻辑了。
走着一圈之后, 写完了上面自己的总结, 现在复制大佬的答案:
@bnu_chenshuo 从发生 retransmit 的间隔看,太规律了。我现在怀疑是 aws 有意限速,通过非常巧妙的少量丢包或乱序(图一中粗线下挂的小黑点),并控制 RTT,让 Linux TCP sender 的 cwnd 钳制在几十 KB,RTT 在 10ms,进而限制吞吐量在几千 KB/s。
我在 t3.micro 上用 FreeBSD 13 复现。观察到 AWS 先用对付 Linux 的办法:故意丢包乱序 + RTT=10ms,发现不灵之后,恼羞成怒,包也不丢了,直接卡脖子。总之就是不让你白嫖网速。对 Linux 是智斗,每秒钟丢你一两个包,RTT=10ms,让你自己cwnd小、速度上不去,你也不好说啥。对 FreeBSD 就上武力了。
???对于测试的结果, 我这边确实不同,我读取到的RTT 60ms 明显要比大佬测试的时候的RTT 10ms 更高. 我把这个理解为 中国区AWS 与 Global的差异, 这个问题也许还能继续分析?
调整 rmem , wmem 的大小到 MTU * CWND = 9001 * 60 = 540600 ,这个数值x2 设置到发送和接收的窗口, 重新抓包, 理论上应该看不到快速重传了。并且拥塞窗口应该是稳定在 60 左右。
测试的过程中观察, 设置 rmem wmem 最终的值为 1000000, ss命令中的 CWND稳定在 57 , 抓包的结果中没有快速重传, RTT也比较稳定了, 不再有跳跃和突然增加到 100+ 的RTT, 速度还是被限制了, 这时候较小的是 RWND, 所以也是为什么 CWND 可以比较稳定不再变化的原因。
Topic 2 如何使用wireshark查看丢包率?
如何查看实例在限速状态的 丢包率 和 重传率?
在客户端的抓包结果里面, 使用字段 tcp.stream eq 0 and tcp.analysis.fast_retransmission 调整到对应的 tcp stream, 然后在Conversion
s窗口中统计的 Percent Filter 里面的百分比就是重传率, 丢包应该是 : tcp.analysis.lost_segment
或者就直接使用IO Graphs, 然后可以看到下面的图像,可以看到这个丢包比较小, 所以我在Y轴设置 100 的 Factor, 这样看起来清楚些。
如图:
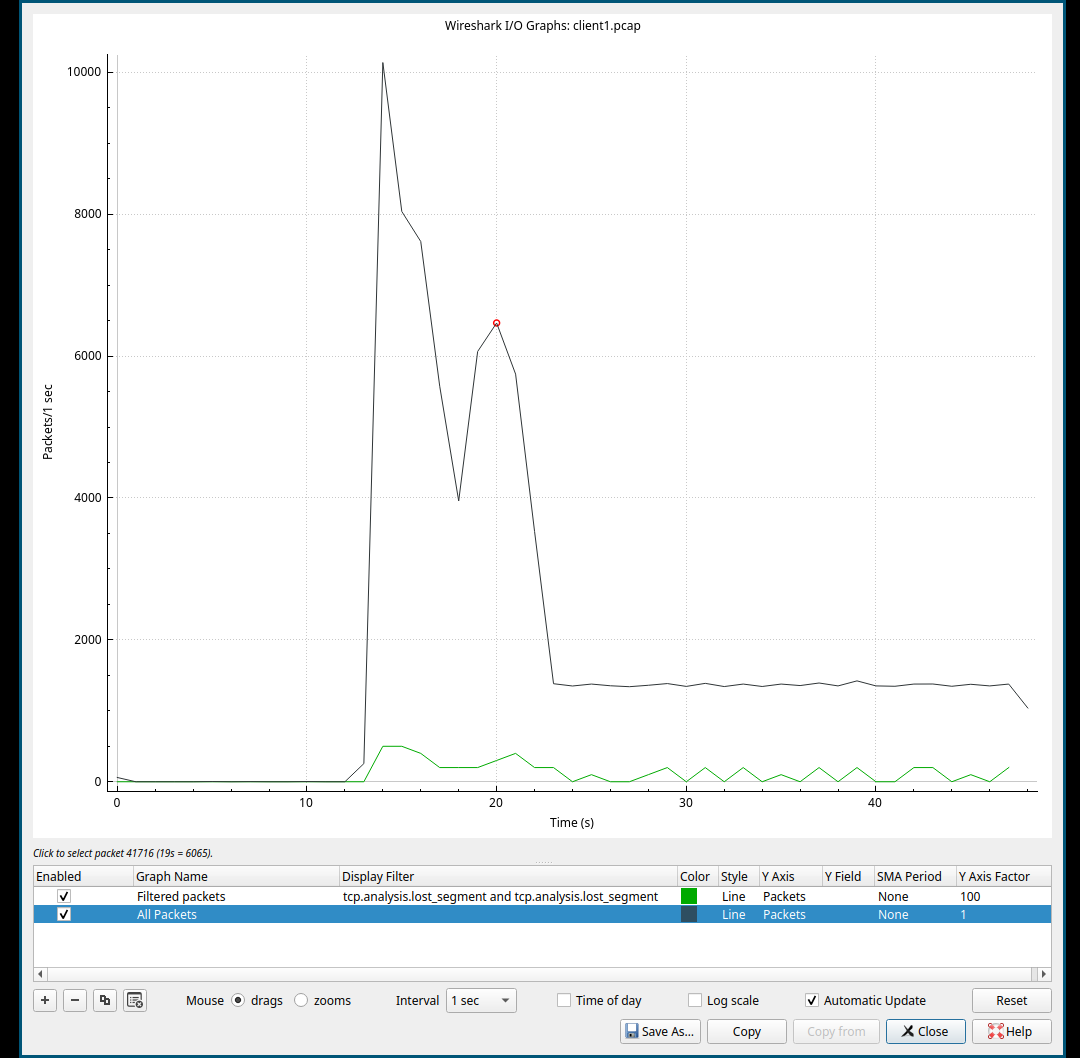
基于这个抓包结果里面的基本上是乱序和快速重传,Server是发送数据的源头, 客户端没有收到认为这个是丢包。
那么感觉丢包率看Client的抓包结果应该就可以。 查看重传率 从Server这测的抓包结果来看。
Topic 3 RTT的变长是不是流控可以设计的?
这个rtt确实无法区分到底是底层的流控带来的, 或者是设计故意拖长的,更新额外测试的结果:
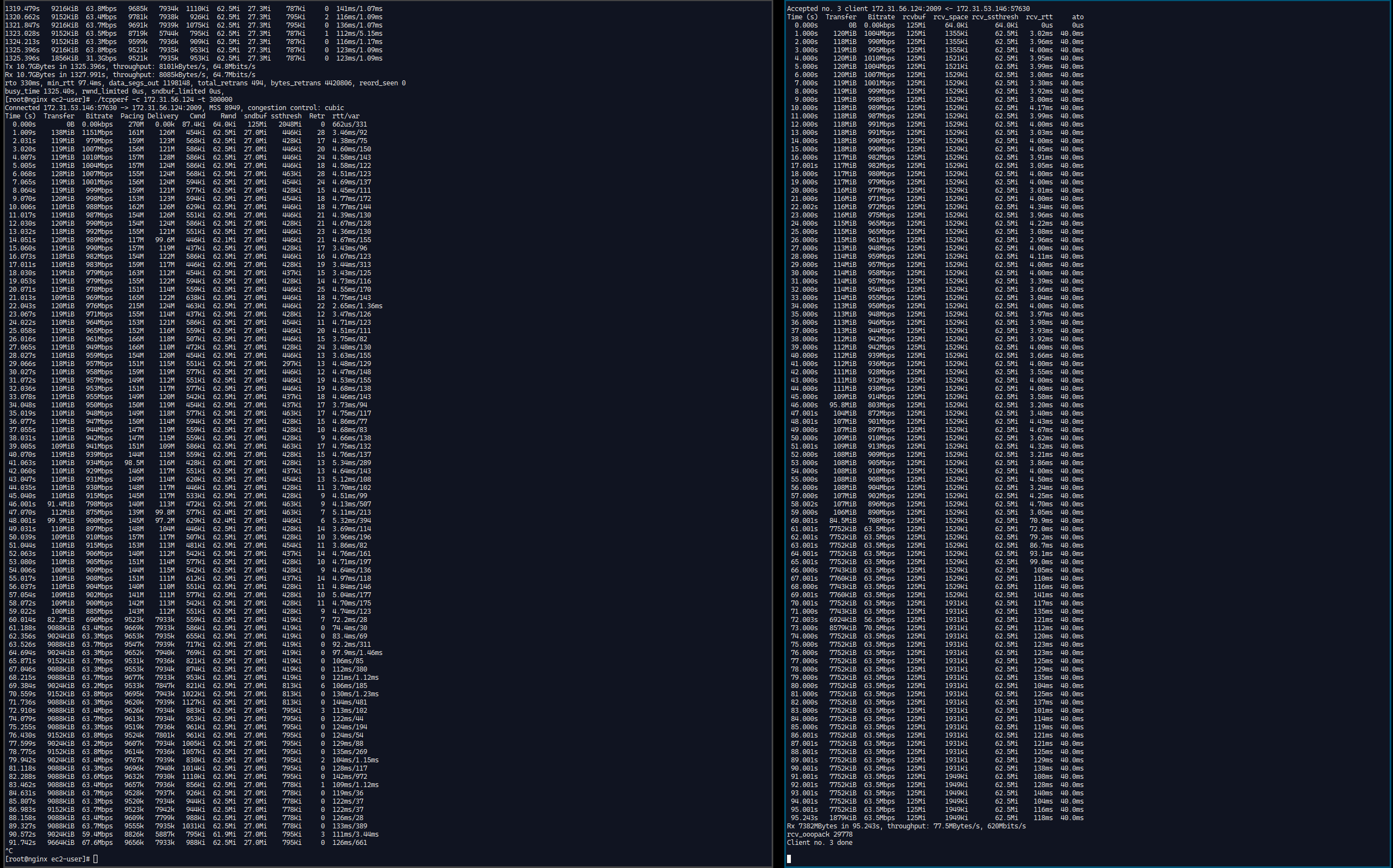
将三个实例完全换成 c5.large, 后续没有RTT非常高的的问题了, 如图:

尝试处理掉CPU 的 IOwait, 也就是将这个文件缩小到 500MB ,之后nginx的数据都从内存取出, 发现RTT增加到了120ms, 维持了较长的时间之后还会回到60ms, 不知道这个原因是什么, 但是看起来RTT不稳定可能确实和os本身没什么关系。
试试其他规格的实例: 尝试在c5的实例上面直接使用tc卡住网桥设备的带宽, 来模拟链路中的网络设备? 观察rtt看看是否有任何的变化。
测试的方法使用docker-compose启动两个pod, 文件如下:
1 |
|
在docker容器里面放入 Shuo Chen 大佬的tcpperf二进制文件,然后我在pod2里面启动 -s, 然后在br上面加tc控制带宽。
1 | tc qdisc del dev "br-9f86ad93edf1" root |
在测试pod1与pod2 的带宽, 他们的通信速度非常快, 10G的文件几秒就发送完了, 并且br上面的限制没有生效, 感觉应该是直接走了os的协议栈, 其他的部分都没过, 所以没法继续测试。
转而使用host os上面的 tcpperf 去发送数据到容器内, 带宽确实被限制了, 但是RTT依旧很低。
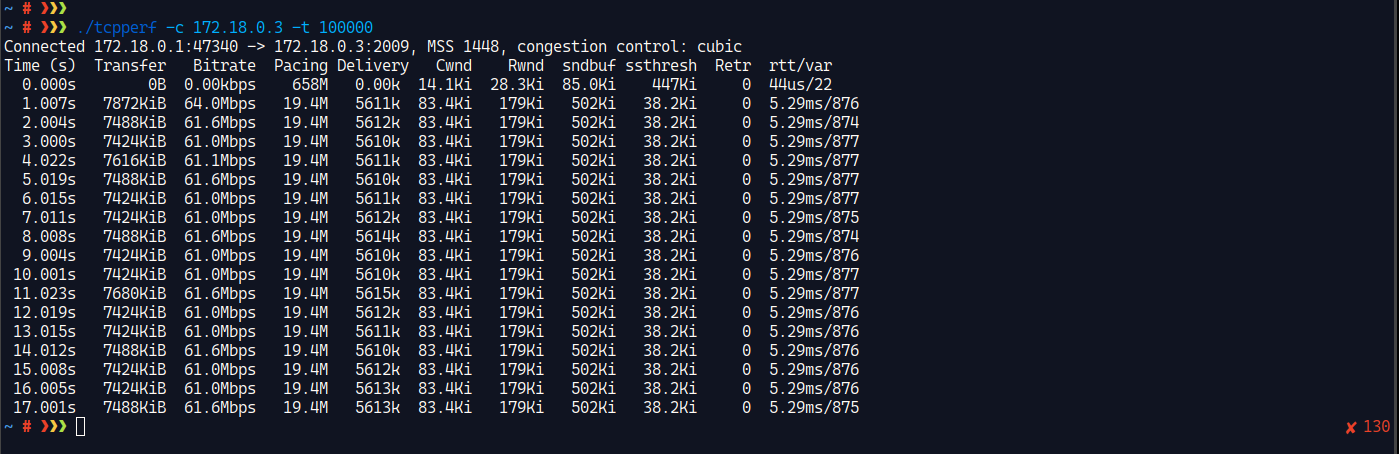
看起来思路是没问题的? 但是好像也确实无法证明RTT升高的最终原因。
Update 2023-05-10
对于这个延迟是不是流控添加上去的, 我得到了两个不一致的答案,
一种说法是, RTT升高是流控刻意为之, 主要的原因是, RTT的翻倍量级比较大。
另一个说法是, 没有给网络添加延时, 这不符合逻辑, RTT增高确实是不合理的现象。
Update 2023-07-04
我最后找到了原因, 在ENA驱动程序的文档中是这样描述流控这个行为的:
当实例的网络流量超过最大值时,AWS 将通过排队然后丢弃网络数据包来调整超过最大值的流量。您可以使用网络性能指标监控流量何时超过最大值。这些指标可以实时告知您对网络流量的影响以及可能的网络性能问题。
基于上面的描述就可以确认, 延迟高的原因是 队列 , 丢包的原因是控制操作系统的TCP协议, 让 TCP 协议来遵守底层的规则。 看到了相关的指标, 两者是分开的。

