Linux OS 网络流量控制测试
内核参数的说明
对于 TCP 来说,会遇到如下的几个参数。
如果我们需要查看一下当前 OS 内与 tcp 相关的 Kernel 参数, 命令如下:
1 | ]$ sysctl -a | egrep "rmem|wmem|tcp_mem|adv_win|moderate" |
其中主要需要关注的是:
1 | net.ipv4.tcp_rmem = 4096 131072 6291456 |
这两个参数表示的是当前内核预留的 Socket Buffer, 单位是Bytes, 也是具体指 内存 的大小。具体的说明我找到 Kernel文档的说明如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
min: Minimal size of receive buffer used by TCP sockets.
It is guaranteed to each TCP socket, even under moderate memory
pressure.
Default: 4K
default: initial size of receive buffer used by TCP sockets.
This value overrides net.core.rmem_default used by other protocols.
Default: 87380 bytes. This value results in window of 65535 with
default setting of tcp_adv_win_scale and tcp_app_win:0 and a bit
less for default tcp_app_win. See below about these variables.
max: maximal size of receive buffer allowed for automatically
selected receiver buffers for TCP socket. This value does not override
net.core.rmem_max. Calling setsockopt() with SO_RCVBUF disables
automatic tuning of that socket's receive buffer size, in which
case this value is ignored.
Default: between 87380B and 6MB, depending on RAM size.
tcp_wmem - vector of 3 INTEGERs: min, default, max
min: Amount of memory reserved for send buffers for TCP sockets.
Each TCP socket has rights to use it due to fact of its birth.
Default: 4K
default: initial size of send buffer used by TCP sockets. This
value overrides net.core.wmem_default used by other protocols.
It is usually lower than net.core.wmem_default.
Default: 16K
max: Maximal amount of memory allowed for automatically tuned
send buffers for TCP sockets. This value does not override
net.core.wmem_max. Calling setsockopt() with SO_SNDBUF disables
automatic tuning of that socket's send buffer size, in which case
this value is ignored.
Default: between 64K and 4MB, depending on RAM size.
这文档中的说明,默认的三个值分别是: 最小, 默认, 最大。测试了一下, 如果只是需要实际调整的话, 调整那个最大值即可, 在高延迟的链路中, 调整默认值或者最大值就可以生效。 在测试的过程中, 将三个值都写成一致,控制变量。
对于TCP协议的接收与发送两方, 各自有自己的 RecvBuffer 和 SendBuffer, 发送方会考虑链路上面可以承载的数据量(带宽), 以及 对方可以承载的数据量(rmem)参数使用的内存用量。
实际上, 只是更新 max 的值, 并不会更新 Recvbuffer.
如果想增大 receive buffer 的大小, 可以增加 tcp_rmem 的 default 的值大小.
测试环境
两个 EC2 c5.2xlarge, 其中一个部署 Nginx , 并使用如下配置文件部分设置 , 发布一个 Fedora ISO, 大小大约 2G。另一个上面只是客户端, 使用的访问客户端是Curl。
1 | http { |
测试准备
测试的过程其实涉及了四个部分的 延迟 问题:
- 发送方的应用程序性能。
- 发送方的发送缓冲区大小, SendBuffer
- 接收方的接收缓冲区大小, RecvBuffer
- 接收方的应用程序性能。
调整延迟和控制带宽 , 这两个部分控制的都是网络传输部分的性能,测试的过程中默认认为 发送 以及接收方的性能都完全没有问题。
基准
两个机器的内核参数使用默认值, 先通过 tc 流量控制注入一些延迟, 查看并分析RTT对于传输速度的影响。
两个server之间默认的内核参数:
服务端参数
1
2net.ipv4.tcp_rmem = 4096 131072 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304客户端参数
1
2net.ipv4.tcp_wmem = 4096 131072 6291456
net.ipv4.tcp_rmem = 4096 16384 4194304
curl 的 测试命令 如下:
1 | ~]$ curl -o /dev/null -s -w "time_namelookup:%{time_namelookup}\ntime_connect: %{time_connect}\ntime_appconnect: %{time_appconnect}\ntime_redirect: %{time_redirect}\ntime_pretransfer: %{time_pretransfer}\ntime_starttransfer: %{time_starttransfer}\ntime_total: %{time_total}\n" http://nginx.liarlee.site/Fedora-Workstation-Live-x86_64-38_Beta-1.3.iso |
如果使用默认的参数, 那么2G的 ISO 文件可以快速的传完, 这是两个实例的基准表现, 这也是创建了一个TCP Connection 的较好的性能表现, EC2 之间的带宽 10Gbps。
1 | % Total % Received % Xferd Average Speed Time Time Time Current |
总体看起来使用了 2s 不到的时间, 就传输完成了2G的文件。
仅控制带宽
在添加了带宽 控制, 带宽控制在 1000Mbps, 带宽监控结果:
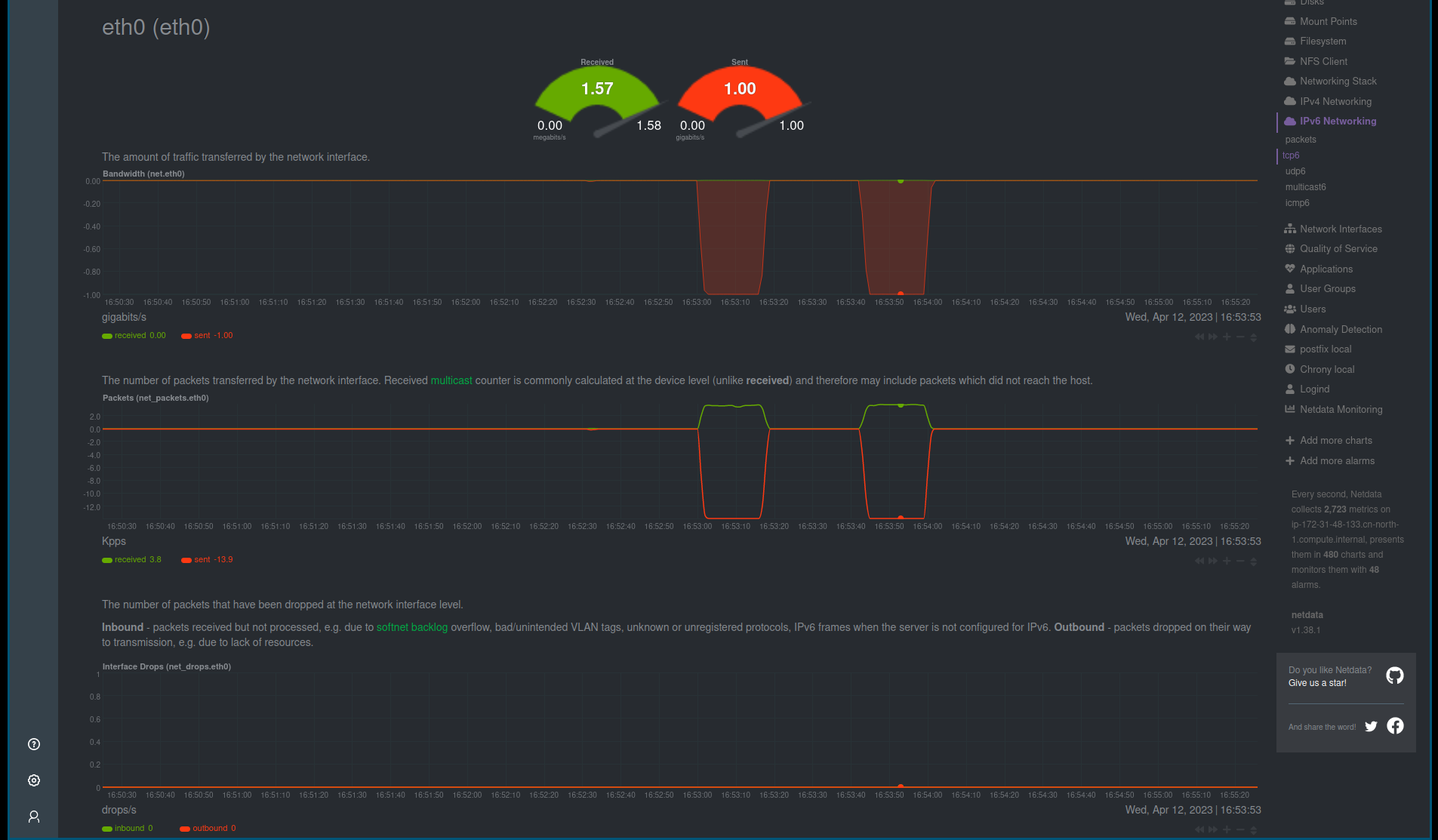
Curl命令的结果:
1 | % Total % Received % Xferd Average Speed Time Time Time Current |
在仅仅控制带宽的前提下, 由于延迟忽略不计, 所以传输的数据量可以使用全部的带宽,这个场景下面传输的速度取决于网络带宽的大小, 网络带宽越大, 传输的数据量和速度都会相应的增加。
控制带宽+延迟
给服务端添加一个 50ms 的 延迟, 使用 tc 工具, 参考文档, 命令如下:
1 | tc qdisc del dev eth0 root |
测试的时候使用curl命令, 将结果直接输出到 /dev/null, 这个场景下, 客户端收写数据的速度非常快,这样的测试排除了大文件落硬盘速度慢的问题, 但是也让客户端收到这批数据之后立刻可以发送ack给服务端(Client - ACK——> Server), 告知服务端我这边的数据已经处理完了, 回收 RecvBuffer 空间.
在添加带宽控制和 50ms 延迟之后, 带宽使用: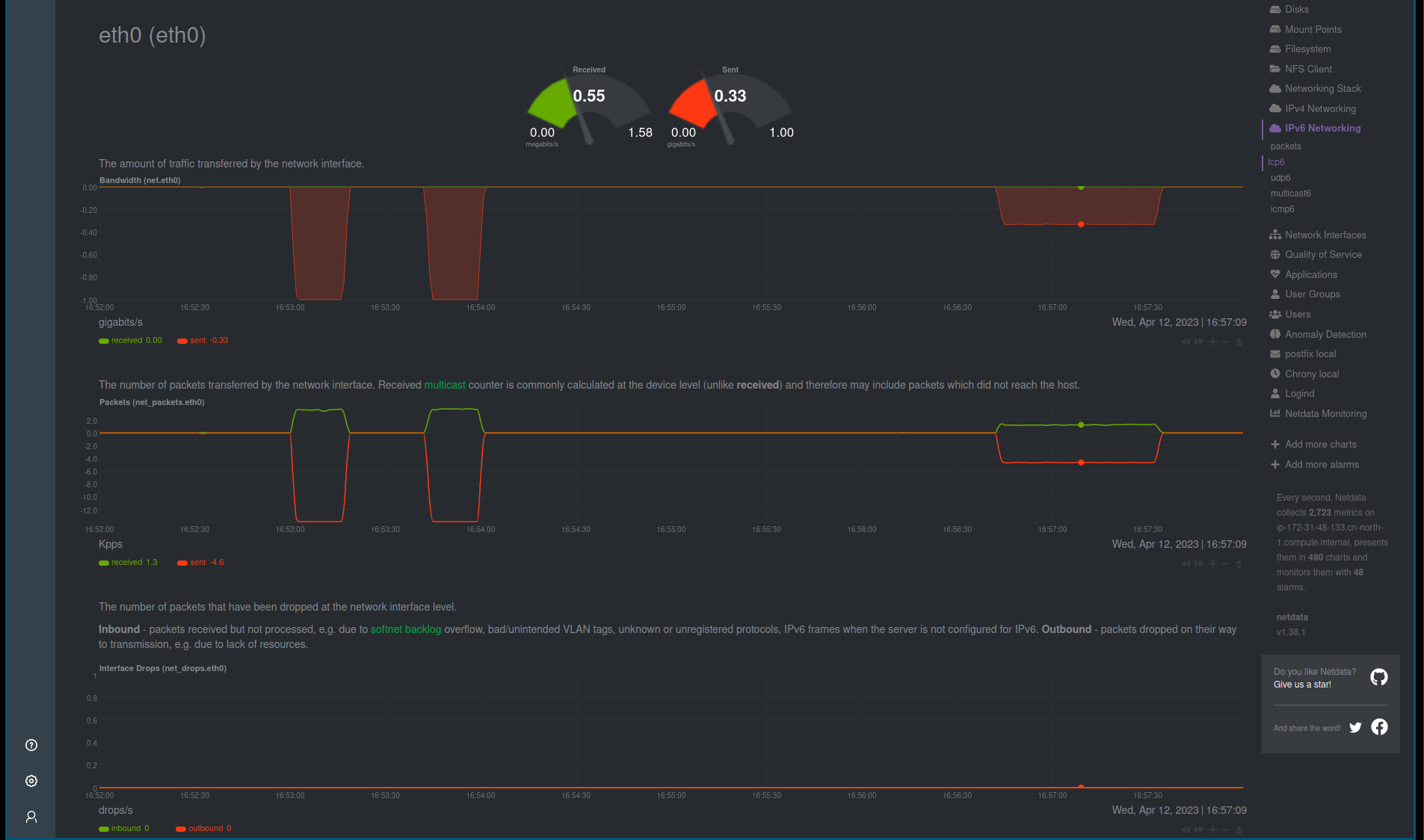
ping 命令 确认 rtt :
1 | root@arch ~# ping nginx.liarlee.site |
curl的结果变成这样:
1 | % Total % Received % Xferd Average Speed Time Time Time Current |
链路的带宽没有被充分利用, 所以发送数据的速度已经慢很多,并且时间也比较长。
在有延迟的情况下, 发送方会按照接收的窗口进行配置。
加入随机延迟
1 | tc qdisc add dev eth0 root netem delay 100ms 10ms # 上下浮动 10ms |
加入丢包
tc子系统可以在网卡上面直接控制丢包的百分比:
1 | tc qdisc add dev eth0 root netem loss 1% # 随机丢 1% |
配置到特定IP地址的流控
有的时候故意测试非常奇怪的场景, 如果加在eth上面就会很奇怪, 整体的流量都被影响了, 那么最简单的设置就是限制一下生效的范围:
指定IP地址延迟17ms
1 | tc qdisc del dev eth0 root |
指定IP地址和端口触发延迟
1 | 这个太难了 我不会 , 后面在看吧, 感觉暂时用不到, 限制到IP地址就可以了。 |
理论说明以及后续测试
如果我的网络延迟小到可以忽略不计,那么这个时候发送方缓冲区里面的数据基本上就是实时抵达对方, 并且立刻可以接收到对方的ACK报文, 这样无论我的发送和接收的Buffer有多小或者多大都无所谓, 数据包都可以快速的发送出去, 然后被确认收到。
在添加了网络的延迟之后, 50ms, 那么这个时候链路上面可以承载的数据包计算方式如下:
1000Mbps/8 * 0.05s (rtt)= 6.25MB # BDP 带宽延时积
6.25MB * 1024 = 6400KB * 1024 = 6553600 Bytes
6553600 * 2 = 13107200 # 这个是linux kernel buffer size
在这个测试的过程中发现, 数据发送方的通告的window size, 固定是 tcp_rmem 值的一半。 发现这个是 BDP 计算出来的结果是 6553600, 如果这个值直接配置到tcp_rmem中,抓包出来windowsize就正好是预期的一半, 这会导致限定的千兆带宽正好占用500Mbps。
buffersize 设置成了 2倍 的 接收窗口的原因是: Linux Kernel 的参数 net.ipv4.tcp_adv_win_scale = 1, 内核文档中的说明如下:
1 | tcp_adv_win_scale - INTEGER |
由于这个值 当前的主流版本可能都是1 , 所以默认会用一半的rmem空间来通告自己的接收窗口大小,但是这参数的取值范围写的是 -31 到 31 , 但是大部分写的都是 1 0 -1 这三个值, 感觉网络上面目前没有正确答案呢?
https://unix.stackexchange.com/questions/94770/what-does-net-ipv4-tcp-app-win-do
https://emacsist.github.io/2019/07/13/linux%E7%BD%91%E7%BB%9C%E7%9B%B8%E5%85%B3%E5%8F%82%E6%95%B0/
测试1 增加客户端的 Rmem
服务端参数
1
2net.ipv4.tcp_rmem = 4096 131072 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304客户端参数
1
2net.ipv4.tcp_wmem = 4096 131072 6291456
net.ipv4.tcp_rmem = 13107200 13107200 13107200
接下来就是调整这个的配置来观察带宽以及传输速度的差异。
带宽使用量: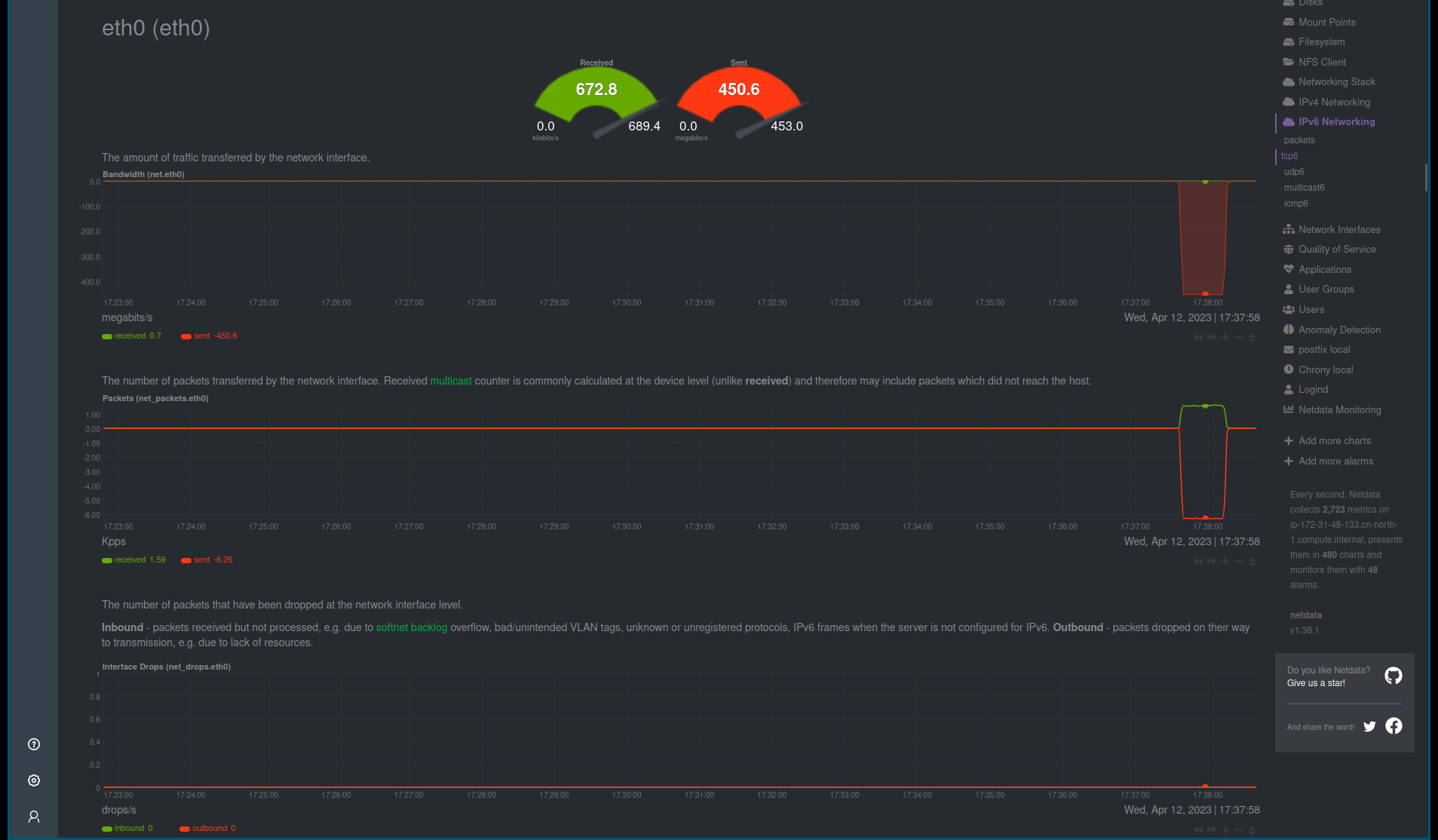
curl 的结果:
1 | % Total % Received % Xferd Average Speed Time Time Time Current |
测试2 增加服务端的 Wmem
服务端参数
1
2net.ipv4.tcp_wmem = 13107200 13107200 13107200
net.ipv4.tcp_rmem = 4096 16384 4194304客户端参数
1
2net.ipv4.tcp_wmem = 4096 131072 6291456
net.ipv4.tcp_rmem = 13107200 13107200 13107200
带宽的结果:
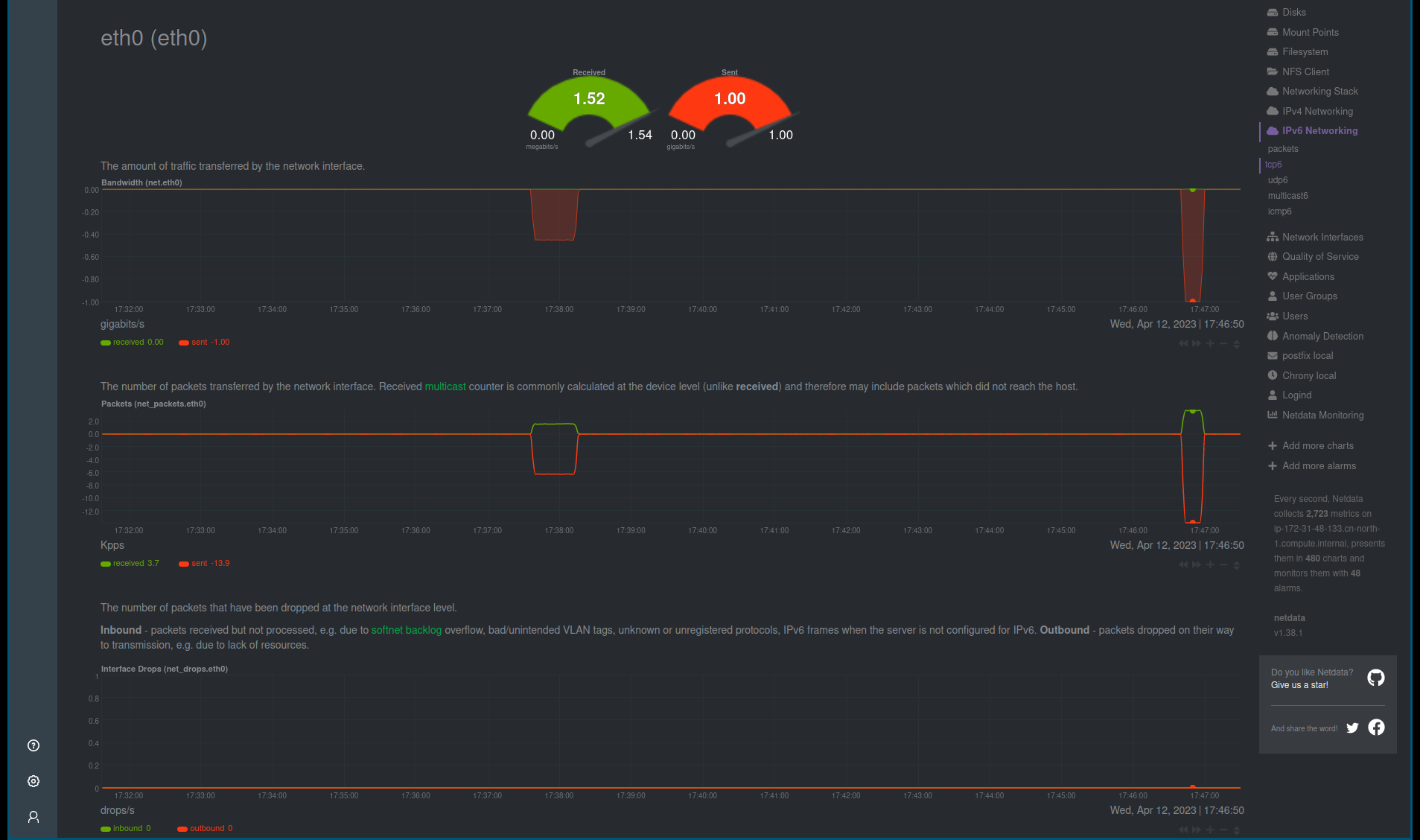
curl 的结果:
1 | % Total % Received % Xferd Average Speed Time Time Time Current |
从当前的结果来看, 现在已经可以用满全部的带宽了, 查看抓包的结果, 发送和接收数据非常连续。 中间的停顿时间也比较短。
如图:
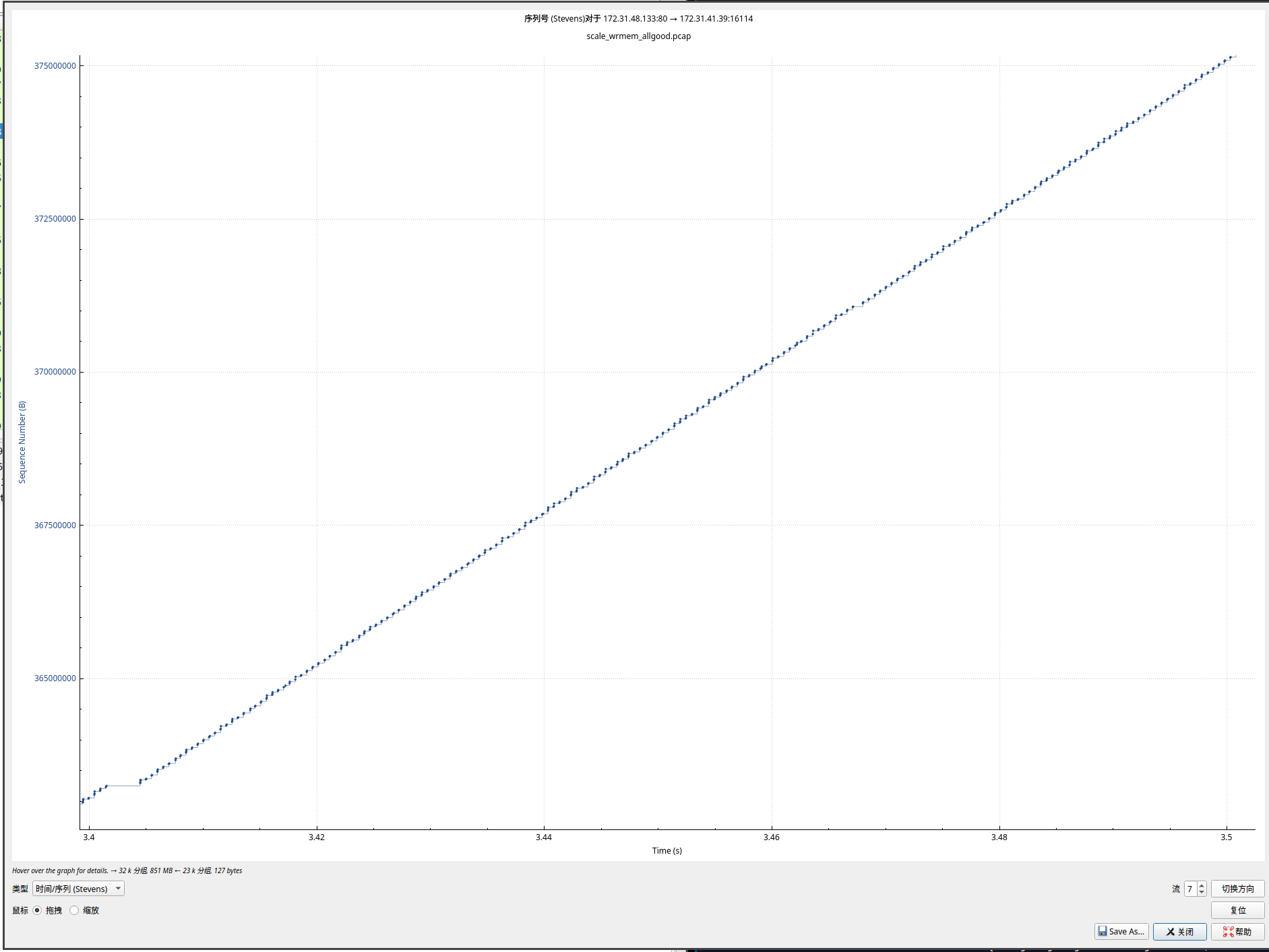
这个结果我还重新反复抓了几次,这个可以跑满带宽 并且可以顶住 50ms 延迟。
TCP慢启动时候的截图:
我将几个字段提取了出来,放在了截图的最前面, iRTT, WindowSize, Bytes in flight。 对于这个结果里面, 我的客户端窗口的变化非常小,传输的后半段 会一直维持在最大值, 但是Bytes in flight 一直都很小, 大概就是 30000 + 的样子。
原因是由于curl在获取到数据包之后快速的ack了收到的包, 然后向服务端更新了接收窗口, 由于curl的动作太快了, 所以我的 Bytes in flight 非常小,窗口一直在被更新, 所以窗口的尺寸非常大, 而且稳定。NOTE: 这个逻辑的证据是: 测试4, 让curl没有时间收取数据包。
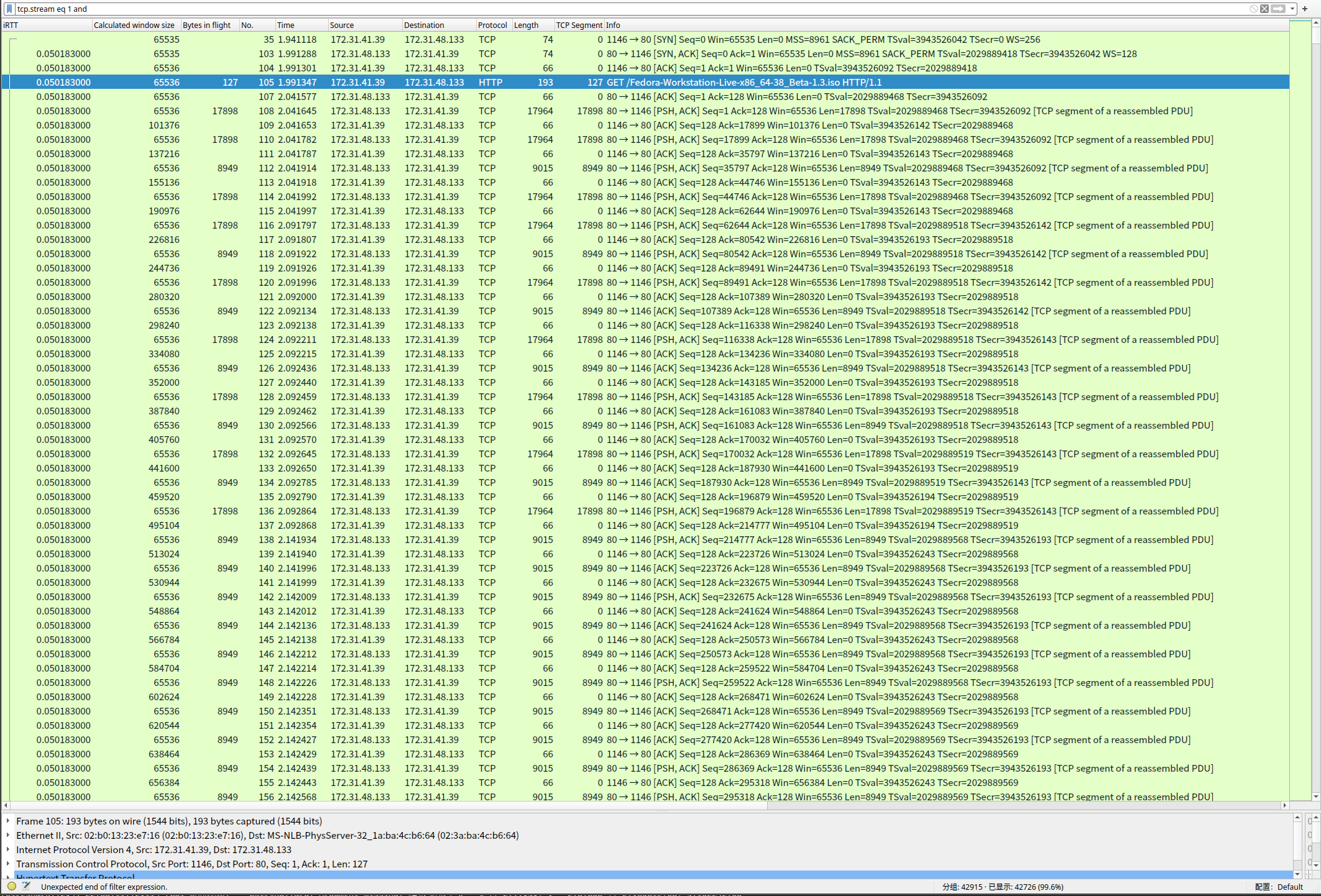
截取了其中的一部分稳定传输中的抓包结果, 如图: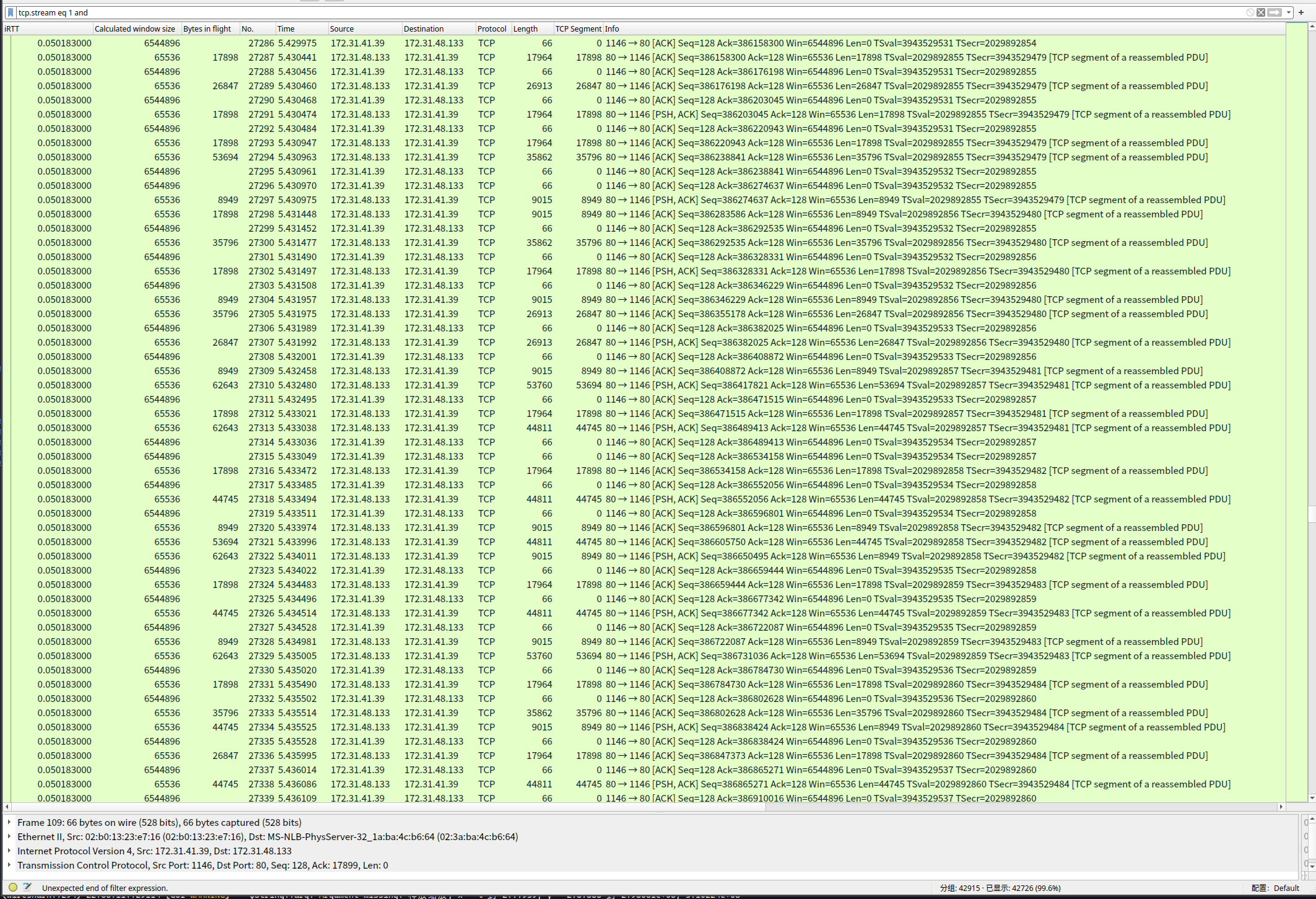
稳定传输中基本上是有空间, 收到之前的ack 就立刻发送新的到链路中.
测试3 锁定 Wmem 以及 Rmem 4096
服务端参数
1
2net.ipv4.tcp_wmem = 4096 4096 4096
net.ipv4.tcp_rmem = 4096 16384 4194304客户端参数
1
2net.ipv4.tcp_wmem = 4096 131072 6291456
net.ipv4.tcp_rmem = 4096 4096 4096
同时设定两端参数,设置生效之后, 速度变得非常的慢, 数据包基本上发一两个就会触发 WindowFull 的提示。改客户端的rmem参数, 会导致 rmem 的容量不够大, 频繁的触发 WindowFull, 窗口很快就被填充满了, 所以curl的下载速度也非常慢。
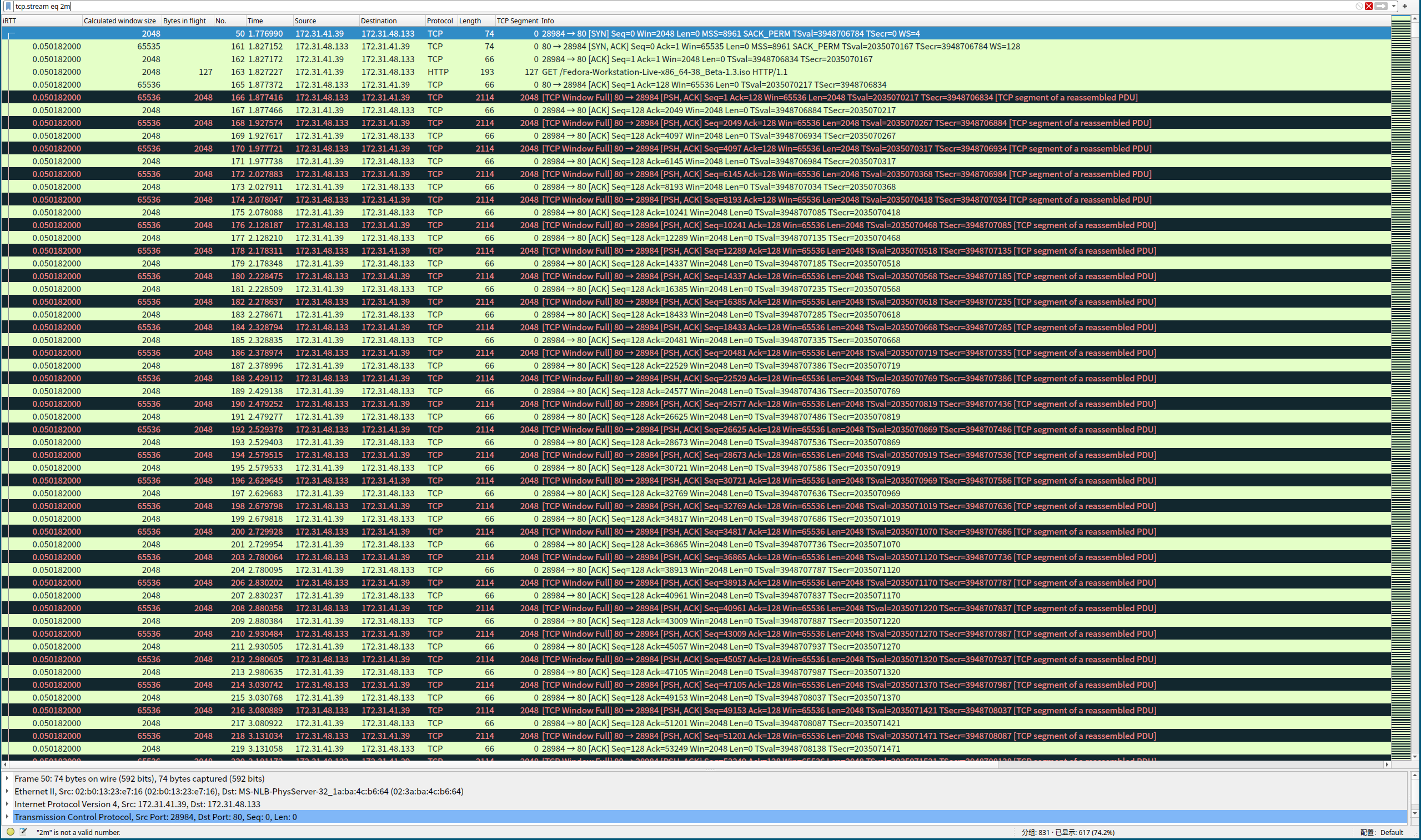
客户端参数不动, 只是改服务端的wmem参数限制到 4096, 传输速度快了一些,但是开始的时候数据包发送的速度比较快, send-q中的指标快速被降低下来,虽然速度变快了一些, 但是不多。我想这个地方还能观察一下Nginx的行为, 应用程序应该也是变慢的。
服务端的参数不动, 只是改客户端的参数,这个时候nginx的sendbuffer里面堆积了许多数据,因为接收的窗口太小, 所以与上面的截图一样,到处都是 WindowFull。
测试4 与curl抢占CPU
运行命令: 启动一个JVM, 跑计算的线程, 这个程序是自己写的,CPU密集型, 运行起来之后就可以使用率100%。
1 | ]$ taskset -c 0 java CPUIntensiveThread & |
测试的结果如图, Recv-Q里面一直有数据, 抓包的结果中显示当前的接收端的窗口是满的, 出现了 WindowUpdate 以及 ZeroWindow的提示。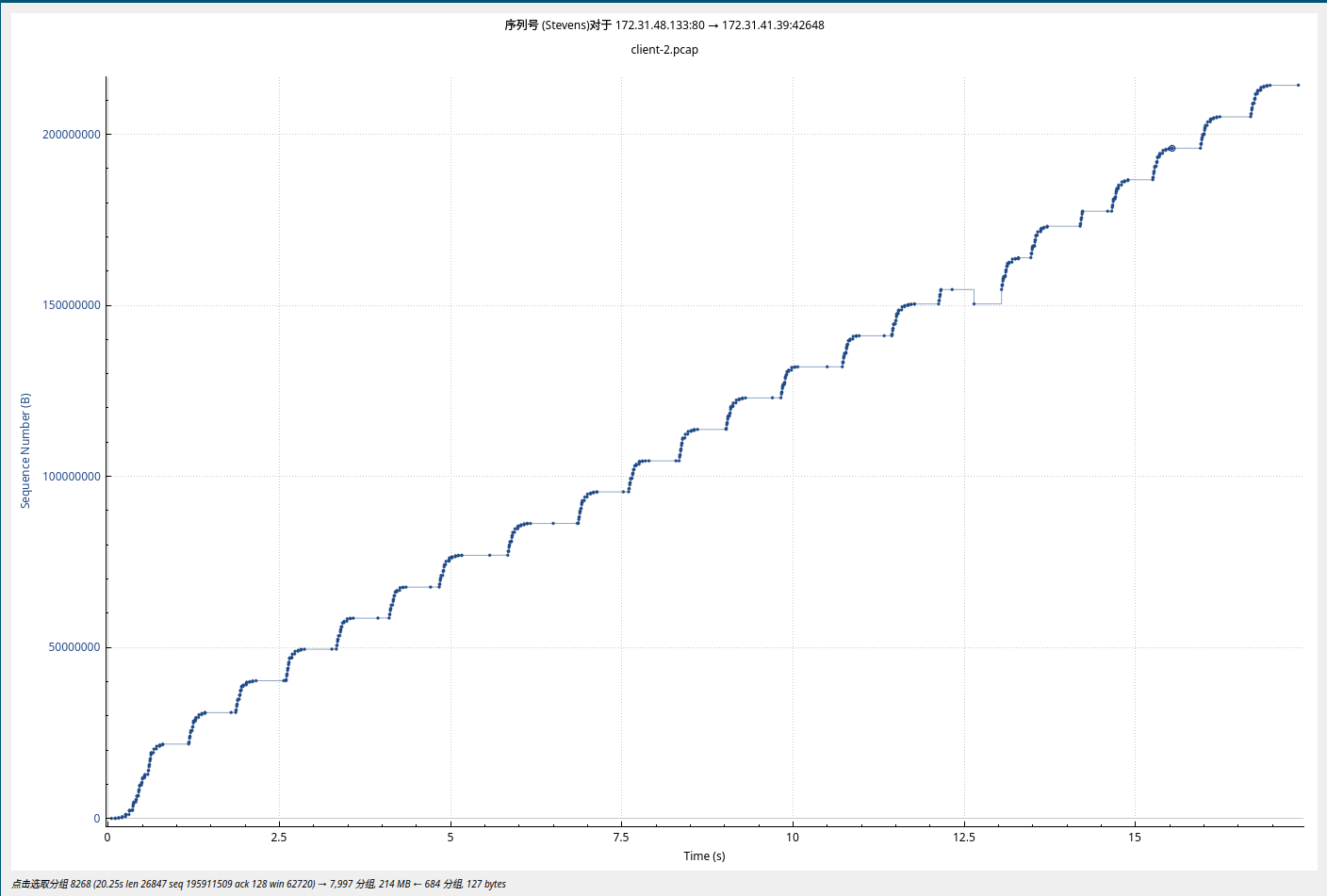
基本上随着窗口的变化而变化, curl的下载速度并不快, 下载的速度也不太稳定。。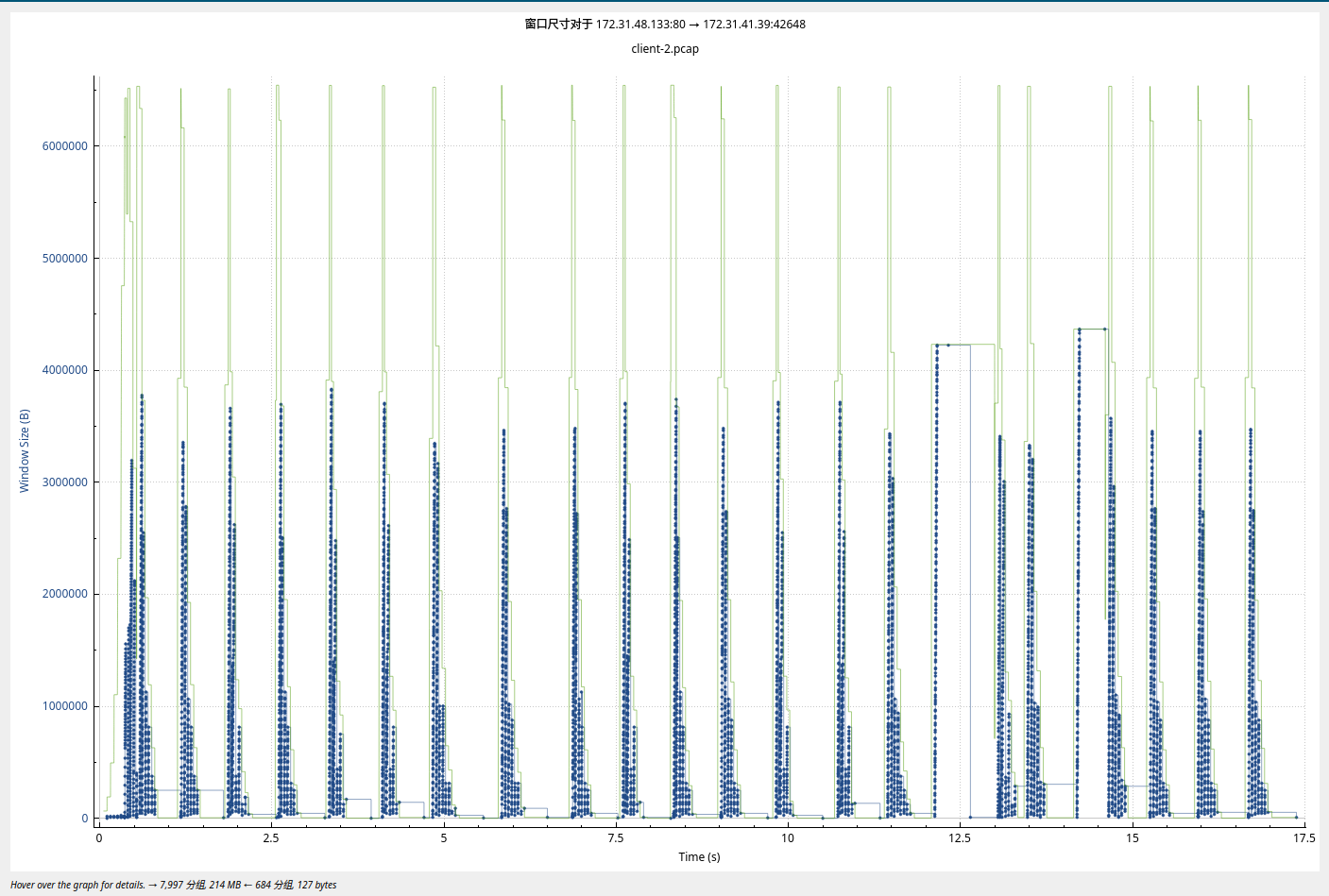
问题汇总
- 如何计算每秒传输了多少MB数据?
- 对于RecvBuffer 或者 SendBuffer 被填满的时候, 应用程序的表现是什么样子的? 我的理解是,应该通过系统调用write()写入的数据在 SendBuffer 满了的情况下, 应用会在等待io的状态。
- wmem的值 与 Send-Q 中的数值的关系是什么?
参考文档
https://tonydeng.github.io/sdn-handbook/linux/tc.html
https://tldp.org/HOWTO/Traffic-Control-HOWTO/
https://blog.csdn.net/dog250/article/details/40483627
https://arthurchiao.art/blog/lartc-qdisc-zh/
关于这个问题的更多解释:
我上面的内容里面可能有一部分图不太好:
https://www.kawabangga.com/posts/4794
这个里面有比较清晰的描述, 例如图里面的每条线是做什么的, 其实看 tcptrace 的那个图像会更清楚。

