删除所有非Running状态的Pod
背景
如果所有的节点上面都有Taint, 然后这个没有Taint的节点磁盘满了, 会导致当前的节点上面留下许多状态不正常的Pod, 这些Pod大概率是停留在了Evicted状态, 或者是Completed, 甚至是 Unknown 。
这种状态的Pod Deployment默认的情况下不会自动回收, 所以需要人工操作一下。
处理方法
记录一个命令来处理这个类型的Pod。
1 | kubectl delete pod --field-selector="status.phase==Failed" |
测试方法
- 集群内两个节点, 其中一个节点Taint
1 | kubectl taint nodes ip-172-31-60-181.cn-north-1.compute.internal app=grafana:NoSchedule |
- 启动30个Grafana
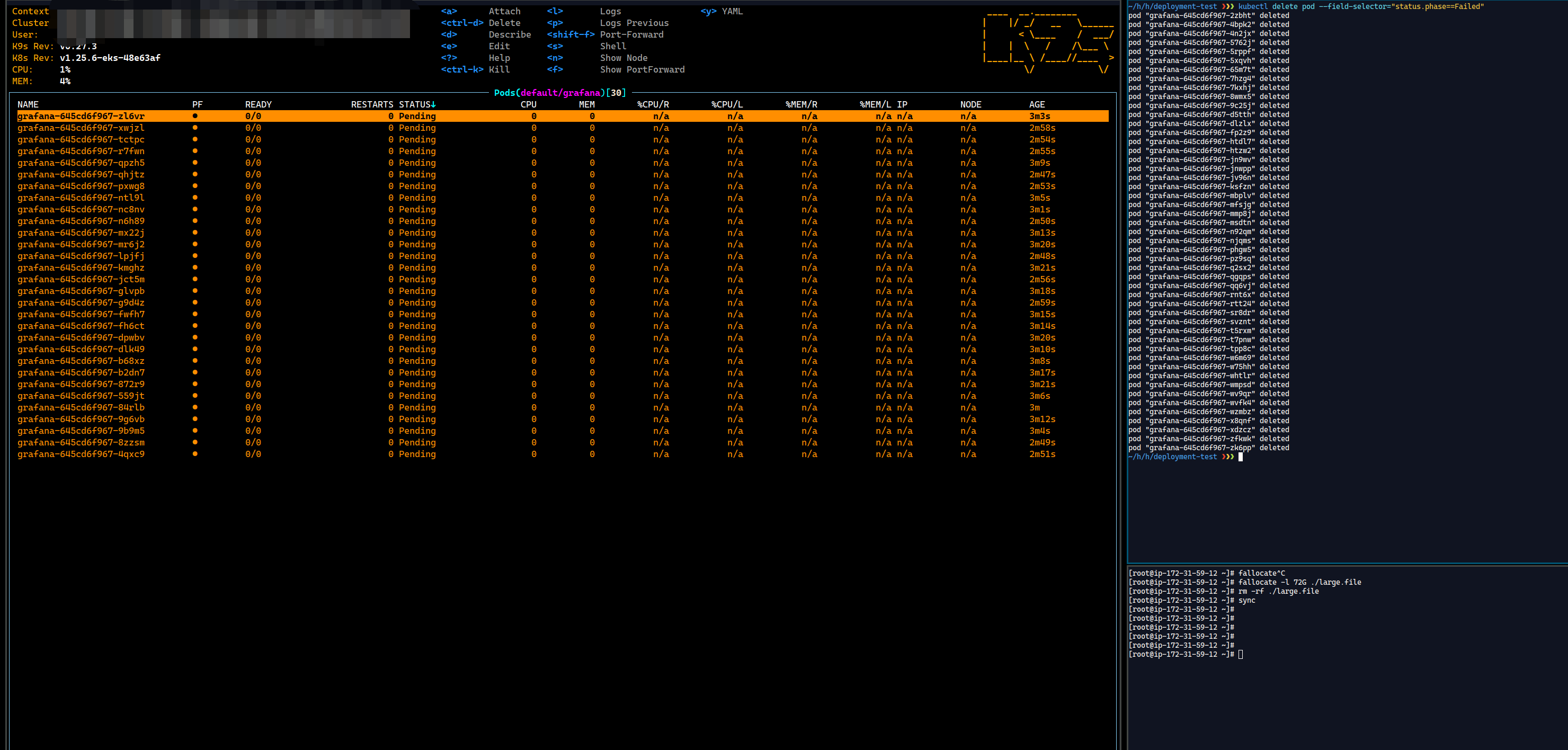
- 登录到节点上面, 创建一个巨大的文件, 触发DiskPressure。
1 | fallocate -l 72G ./large.file |
- 等待节点的DiskPressure被识别, 然后触发驱逐。
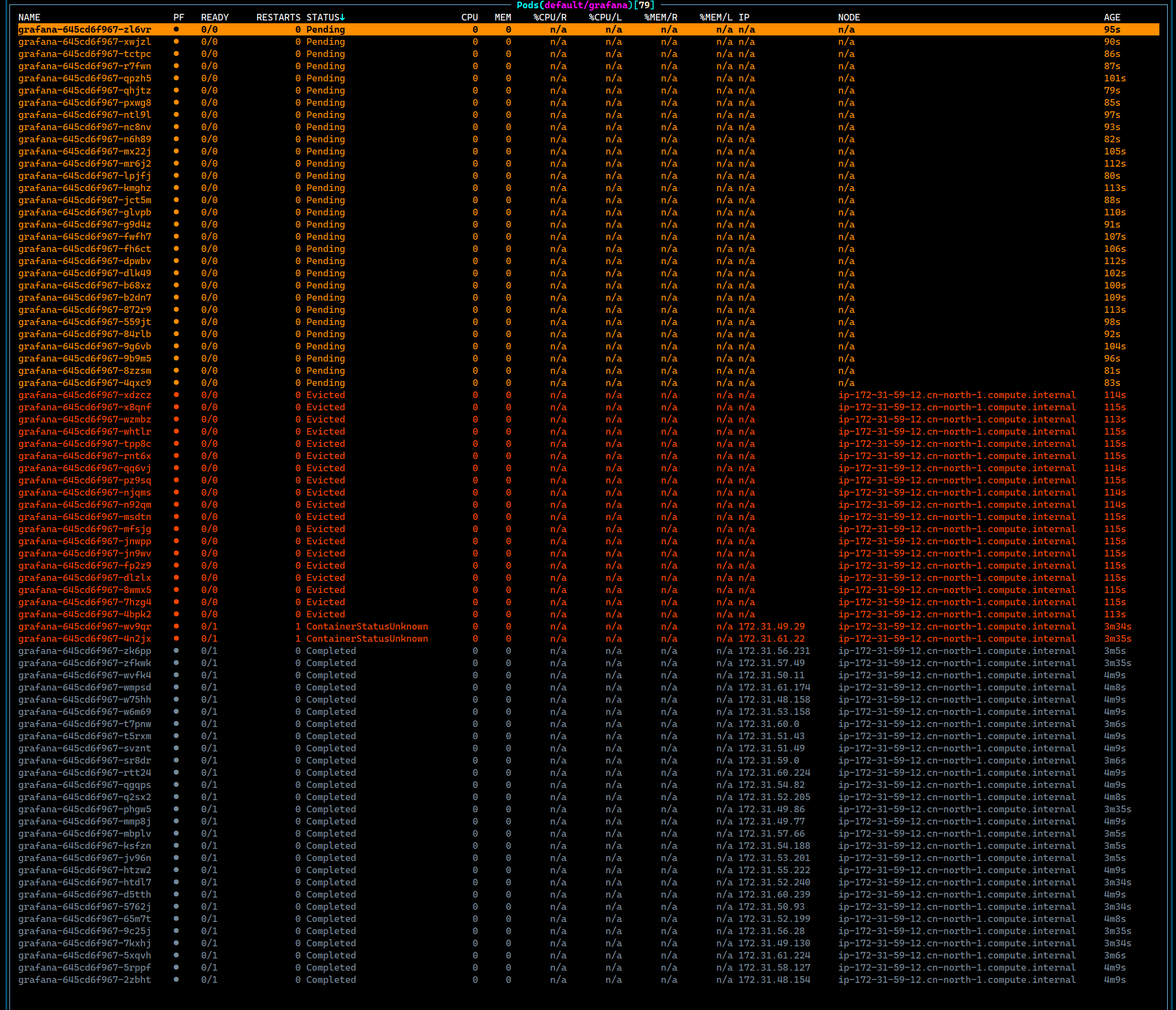
- 删除文件, 取消DiskPressure状态, 等待 30 个新的Pod Ready。
1
rm -rf ./large.file
- 使用命令清除所有不是Running状态的Pod。
1
~$ kubectl delete pod --field-selector="status.phase==Failed"
- Over.
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Liarlee's Notebook!
相关推荐

2024-01-10
源地址检查造成丢包的分析
问题网络访问路径:Client –> NLB –> Application Pod 特别的部分:NLB 开启了保留源地址就意味着 NLB 在转发网络流量的时候不会改变数据包五元组内的SourceIP, 这时候对于后端的Pod和节点来说, 收到的数据包的ip地址来源直接是Client 的IP 地址, 这会导致所有的流量其实都是来自于VPC之外的。 NLB在这其中变成了一个透明代理。从 NLB 发到后端application pod 中的流量会有偶尔timeout的情况, 并不是所有的请求都会timeout ,从客户端抓包显示tcp握手的时候就没有成功, 第一个syn包出去就一直没有回复,然后继续重发等待。 由于后端的pod比较多, 并且nlb在四层做了负载均衡,很难定位到某次的请求具体到了哪个后端pod上面。 写下这些的时候我已经知道了问题的答案是由于 VPC CNI 的一个 env , AWS_VPC_K8S_CNI_EXTERNALSNAT 会指定是否做 SNAT, 比较早的版本, cni 插件没有对 SNAT 在iptables上面进行标记和处理, 这样会导...

2023-08-05
serviceAccount 获取 Token 以及权限的方式
手动获取Token 并发送请求给容器接口。 12345678910/var/run/secrets/kubernetes.io/serviceaccount $ pwd/var/run/secrets/kubernetes.io/serviceaccount $ cat ./tokeneyJhbGciOiJSUzI1NiIsImtpZCI6ImE3N2JhOGMwY2FjYWEwNDk0MWU4MWM0ODk1Y2JiZjBiOTU2NTA1OTYifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjIl0sImV4cCI6MTcyMTk3ODkxOCwiaWF0IjoxNjkwNDQyOTE4LCJpc3MiOiJodHRwczovL29pZGMuZWtzLmNuLW5vcnRoLTEuYW1hem9uYXdzLmNvbS5jbi9pZC9DMEE5NzJGNERCMThBOTMxN0RBMzk0Q0MwRDMzMjU3RiIsImt1YmVybmV0ZXMuaW8iOnsibmFtZXNwYWNlIjoibW9uaXR...
2023-12-05
Windows Core EKS 节点管理命令
windows 查看磁盘空间的使用情况: 1Get-PSDrive -Name C | Select-Object Name, Free windows 实例的磁盘空间扩容 1234diskpartlist volumeselect volume 0extend 从ecr下载镜像 12345$ecrCreds = (Get-ECRLoginCommand).passwordWrite-Host $ecrCredsctr -n k8s.io image pull -u AWS:$ecrCreds ecr link pull image 需要使用节点的C盘空间, 在节点的磁盘空间不足的情况下,会报错。 12rpc error: code = Unknown desc = failed to pull and unpack image failed to extract layer sha256:9ee7a25f1f619685e0c27cd1f08b34fd7a567f8f0fa789gf9aeb79c72169afa: hcsshim::ImportLayer faile...
2023-12-08
自管理节点加入集群
添加一个自管理的节点 创建集群,启动一个新的 EC2, 登录到已经启动的 EKS 优化 OS 内,准备复制一些脚本过来。 添加EC2的标签: kubernetes.io/cluster/clusterName owned 配置EC2的Instance Profile 控制台获取 Kubernetes APIServer的Endpoint URL 获取 apiserver b64 CA : cat ~/.kube/config 这个文件里面可以找到 ,或者是通过EKS的控制台上面, 找到 Base64 的 CA。 编辑 userdata, 或者 ssh 登录到ec2上面创建一个bash脚本用来调用 bootstrap.sh 12345678910mkdir ~/eks; touch ~/eks/start.sh---#!/bin/bashset -exB64_CLUSTER_CA=API_SERVER_URL=K8S_CLUSTER_DNS_IP=10.100.0.10/etc/eks/bootstrap.sh ${ClusterName&...
2023-07-11
添加一个Redhat到EKS集群, 基于Packer的步骤
Copy From zhojiew 的私有仓库文档, 已经经过授权 ~ 官方提供了基于packer工具的构建脚本 这里手动把相关的步骤执行下,基于redhat9构建一个自定义ami。据称eks优化的ami也是通过以下步骤完成的 手动构建ami拉仓库 123cd /home/ec2-suersudo yum install git -ygit clone https://github.com/awslabs/amazon-eks-ami.git 配置环境变量 1234567891011121314KUBERNETES_VERSION=1.26.4 KUBERNETES_BUILD_DATE=2023-05-11 BINARY_BUCKET_NAME=amazon-eksBINARY_BUCKET_REGION=cn-north-1DOCKER_VERSION=20.10.23-1.amzn2.0.1CONTAINERD_VERSION=1.6.*RUNC_VERSION=1.1.5-1.amzn2CNI_PLUGIN_VERSION=v0.8.6PULL_CNI_FROM_...
2023-12-22
Kubectl Apply 报错 annotation Too long
重装 Prometheus operator 的时候报错, 提示 annotation 太长了,不能 apply 12345678910111213> kubectl apply -f ./setupcustomresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com createdcustomresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com createdcustomresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com createdcustomresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com createdcustomresourcedefinition.apiextensions.k8...