Ceph Cluster 01 - Installation
Ceph 的学习笔记和记录。
开始
部署信息
OS Version: Fedora 34 Server
CEPH Version: v15.2.0 (Octopus) +
DOCKER Version: 20.10.8
配置实例的 Hostname 和网络
1 | vim /etc/hosts |
CONFIG Dnf Repo
1 | # config docker |
INSTALL Docker
1 | [root@ceph01 ~]$ sudo dnf remove docker \ |
INSTALL CEPH
Cephadm tools were default in Fedora Repo, No need to change the repo to tsinghua or aliyun. Just install. WOW ~ Fedora YYDS.
启动一个ceph集群
1 | [root@ceph01 ~]$ cephadm bootstrap --mon-ip 192.168.122.121 --allow-fqdn-hostname |
Please notice the output, context include username and password and dashboard address.
1 | Ceph Dashboard is now available at: |
使用 Ceph Shell 命令来管理集群节点
1 | # temprary use |
维护集群
ADD Hosts
1 | [ceph: root@ceph01 ceph]$ ceph orch host add ceph02.liarlee.site 192.168.122.122 |
ADD Osd
1 | # auto-detect available devices (need time to sync the status 1 by 1) |
MANAGE 服务
1 | reduce mon instance to 3 |
完成
1 | [ceph: root@ceph01 /]$ ceph orch ls |
成果截图
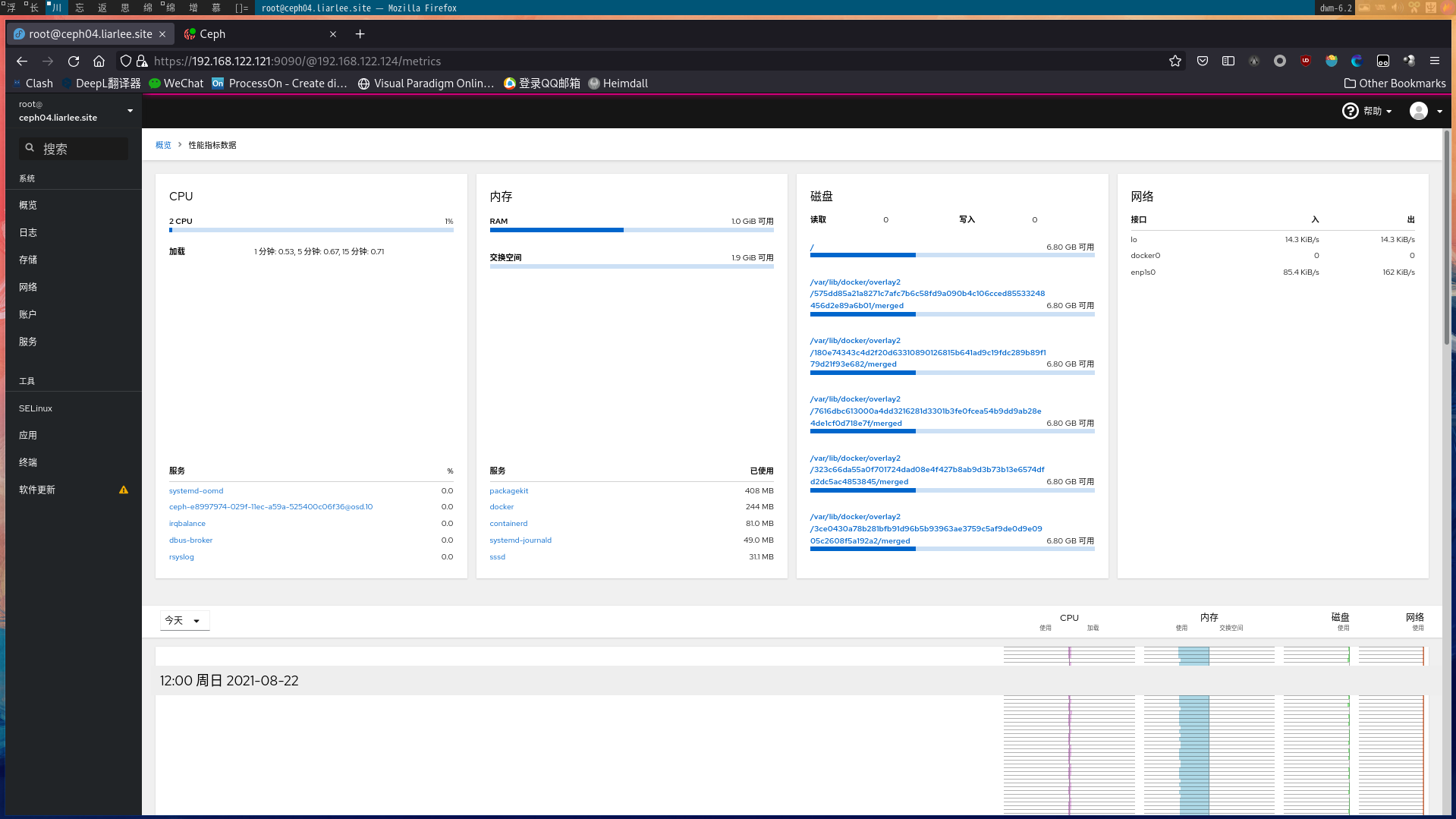
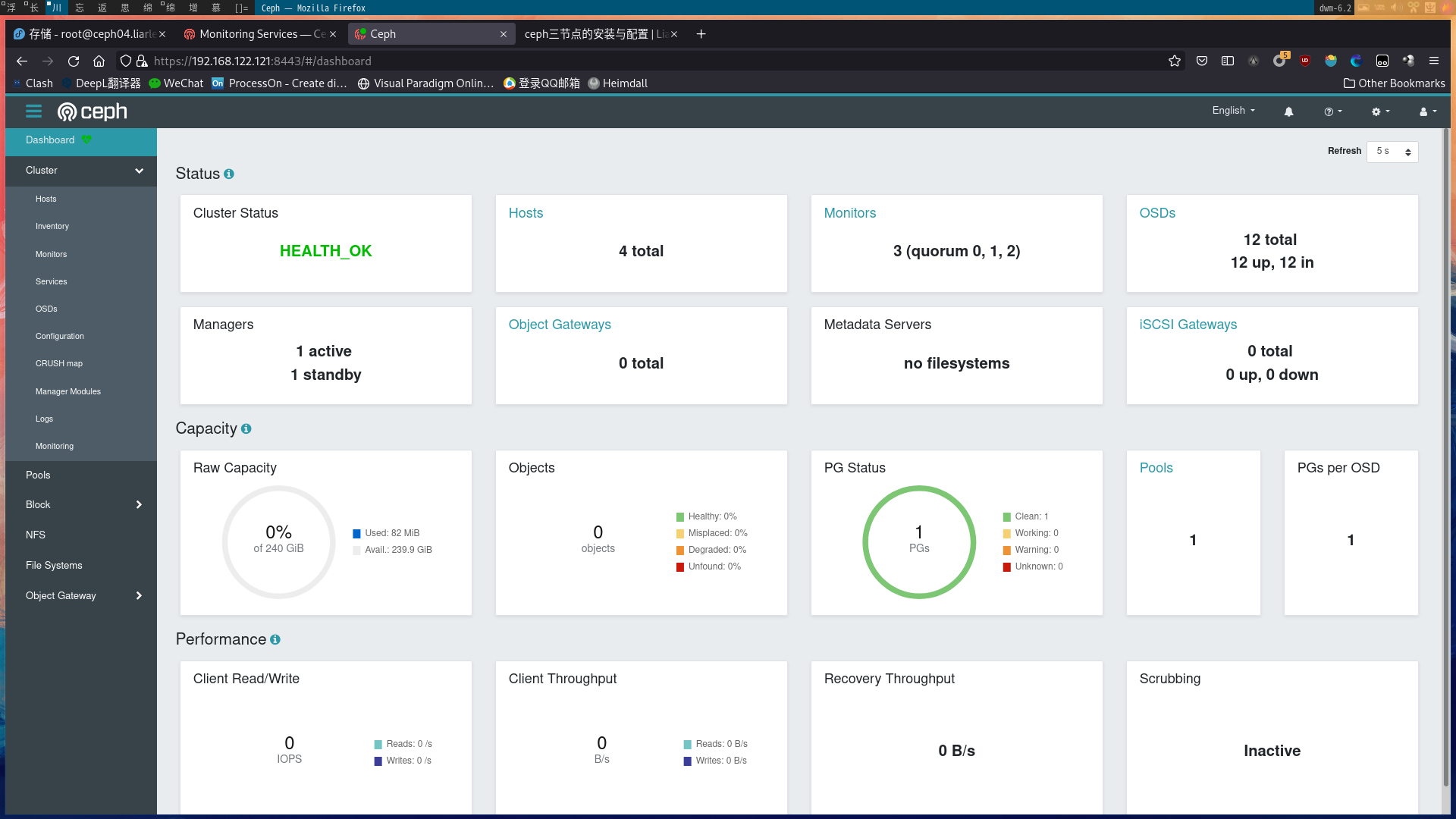
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Liarlee's Notebook!
相关推荐

2021-08-23
Ceph Cluster 02 - OSD/RBD
Ceph的使用笔记。 创建存储池 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120# 创建一个PG为64 ,PGP为64的存储池。[ceph: root@ceph01 /]# ceph osd pool create test-64 64 64pool 'test-64' created# 创建一个自动识别的大小的存储池。[ceph: root@ceph01 /]# ceph osd pool create testpool 'test' created# 查看已经存在的存储池。[ceph: ...
2021-09-01
Ceph Cluster 04 - CRUSH算法
ceph笔记04 修改CRUSH算法的分配方式基础概念:五种运行图: MON服务维护 Monitor Map - 监控的运行图 MON的状态 OSD Map - OSD的状态, 每隔六秒钟汇报一次状态 PG Map - PG的运行图, PG的状态和映射关系 CRUSH Map - 一致性hash算法,和数据块和osd的分配关系, 动态更新,当客户端请求一个文件的时候,会通过CRUSH算法会根据osd的map创建PG组合的来对文件的存储进行负载和分配。假如有20个osd,创建32重组合分配对应的pg和osd的对应关系,选主从,选分布方式和节点的同步关系,叫做CRUSH Map。 MDS Map - Metadata Map ,元数据和数据文件的映射关系。 5种算法对节点的选择方式 Uniform List Tree Straw - 早期的版本,分布不是特别的均衡,抽签算法 Straw2 - 目前已经发展中的版本, 抽签算法 (Default) 对PG的动态调整默认情况下是动态调整的,但是可以手动调整为给予权重,设置PG分配的倾向,例如1T权重是1,等等等等 查看状态以及调整方...

2021-08-24
Ceph Cluster 03 - CephFS
ceph笔记03 Cephfs的使用Cephfs的使用条件 当我们需要多个服务来挂载和实时的同步的时候, 使用到CEPHFS,可以实现文件系统的共享。内核里面现在这个时间已经内置cephfs的挂载模块, 可以直接挂载不需要安装。 cephfs运行需要MDS服务,用来存储缓存的文件信息。总体需要创建两个存储池,单独创建一个存储MDS信息的存储池, 同时需要创建一个数据池来提供存储空间。 启用mds的服务 1ceph orch mds 2 创建ceph的存储池 1234567891011121314151617181920212223242526ceph mds stat# 创建一个cephfs的metadata池ceph osd pool create metadata 32 32 # 创建一个cephfs的data池ceph osd pool create cephfsdata 64 64 # 创建ceph的状态ceph osd pool ls ceph -s # 创建cephfs的文件系统ceph fs new defaultfs metadata cephfsdata#...
2023-08-16
EBS 性能优化笔记
EBS性能优化Agenda 磁盘调优方法论 常用的磁盘调优方法 磁盘压测工具 磁盘性能检测工具 目前比较常用的是 GP3。 方法论应用程序 –》 操作系统 –》 虚拟机 –》 EBS 服务器 应用程序IO请求下发的路径。 三个方向, iops, 带宽, 延迟,按照这三个方面来观察这个EBS本身的性能。 使用新版本的内核: 3.8 以上内核使用的Indirect descriptors 突破 I/O size 44kiB限制, 可以一次请求下发 128KiB的IO大小。 建议使用 amazonlinux 2023 (悲 uname -r 查看内核的版本。 使用 Raid0使用 Raid0 可以提高带宽, 并且节省成本。 能更换磁盘类型达到性能, 可以使用Raid0 不建议在EBS 做 Raid1 5 6 三种, 校验的方式会降低性能。 推荐使用 mdadm , 不一定要用LVM。 关注队列长度SSD: 每 1000iops 队列长度是 1 , SSD是合适的吧 观察队列长度, 如果能达到 IOPS 的情况下, 队列越低越好。 HDD: 1Mi...

1980-12-08
blktrace 命令说明
Blktrace 命令是一款 Linux 内核块设备 I/O 层的跟踪工具。它可以获取 I/O 请求队列的各种详细情况,包括进行读写的进程名称、进程号、执行时间、读写的物理块号、块大小等。 一个I/O请求进入block layer之后,可能会经历下面的过程: Q Remap: 可能被DM(Device Mapper)或MD(Multiple Device, Software RAID) remap到其它设备 G Split: 可能会因为I/O请求与扇区边界未对齐、或者size太大而被分拆(split)成多个物理I/O I Merge: 可能会因为与其它I/O请求的物理位置相邻而合并(merge)成一个I/O D 被IO Scheduler依照调度策略发送给driver C 被driver提交给硬件,经过HBA、电缆(光纤、网线等)、交换机(SAN或网络)、最后到达存储设备,设备完成IO请求之后再把结果发回。 常见的状态切换 Q–G–I–D–C 1234567891011259,2 0 2 0.000001080 71...
2019-06-25
IO重定向笔记
输出重定向部分的复习笔记 标准输入输出文件描述符的概念可以通过命令查看以及绑定文件描述符FD。 123456789liarlee@hayden-pc ~> $ ll /proc/$$/fd总用量 0dr-x------ 2 liarlee liarlee 0 6月 24 20:22 .dr-xr-xr-x 9 liarlee liarlee 0 6月 24 20:22 ..lrwx------ 1 liarlee liarlee 64 6月 24 20:22 0 -> /dev/pts/0lrwx------ 1 liarlee liarlee 64 6月 24 20:22 1 -> /dev/pts/0lrwx------ 1 liarlee liarlee 64 6月 24 20:22 10 -> /dev/pts/0lrwx------ 1 liarlee liarlee 64 6月 24 20:22 2 -> /dev/pts/0 Linux提供的I/O设备Linux系统提供的IO设备,共有三种: STDI...